

At our recent Perceive 2020 conference, Dr. Michela Paganini of Facebook AI Research discussed the latest research in neural network pruning. Pruning means cutting off the unnecessary connections in the neural network to reduce its size. Pruning can reduce parameter counts of trained networks by over 90% which greatly reduces the storage requirements and improves computational performance [1].
The major issue in the pruning process is to identify the "unnecessary". The researchers have come up with a variety of pruning techniques that identifies the "unnecessary" in various ways. Some such techniques are decision tree pruning, neural net pruning, optimal brain damage, and Skeletonization, etc. The main objective, however, for every above-mentioned technique remained the same i.e. remove unnecessary redundancy and unused capacity.
Pruning can be executed before, during, and after training. During fine-tuning the train-prune loop will execute which optimizes the AI model by removing “unnecessary”. In “rewinding” the initialization phase which includes parameter setting is also adjusted. The AI is then trained and lastly pruned iteratively unless optimized parameter settings are achieved.
Structured pruning involves the selective removal of a larger part of the network such as a layer or a channel. Unstructured pruning can be understood as finding and removing the less salient connection in the model wherever they are. Technically speaking, structured pruning prunes weights in groups (remove entire neurons, filters, or channels of convolution neural networks). The unstructured pruning does not consider any relationship between the pruned weights.
Pruning involves the removal of certain data, thus there must be some criteria to remove the data so that the final model performance is not affected. Absolute value is one of the pruning criteria that is generally used to prune the machine learning models. In this technique, each element's absolute value is compared with some threshold value and if its value is below the threshold the element is pruned.
AI models can be developed and run in different computing environments such as cloud, on-premises, and individual devices (PC, phones, etc.). When running an AI model in the cloud the pruning can reduce operational expenditures. On-premises, pruning of AI models can increase the hardware life especially the larger AI models that can be pruned to be run efficiently on older hardware. The same is for individual devices.
So the question arises here, why we actually need a pruned AI model. The major reason is sustainability along with other reasons such as resource constraints.
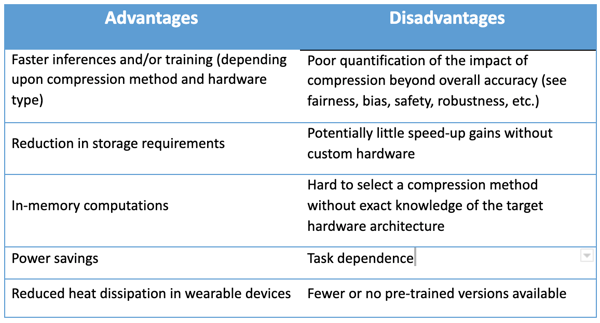
PyTorch is an open-source machine learning framework that helps in pruning and optimizing the AI models. PyTorch can be installed on custom hardware as well as it is supported on major cloud platforms. It enables flexible, fast experimentation and an efficient run environment over a user-friendly front-end.
A pruning container is another tool that stores the history of pruning techniques used and their outcomes. This tool also helps in selecting the optimal pruning techniques.
Similarly, some lines of code are available that can prune a layer in the network, enable iterative pruning, or prune across the global network.
The Frankle & Carbin paper describes the lottery ticket hypothesis as “A randomly-initialized, dense neural network that contains a subnetwork that is initialized such that when trained in isolation it can match the test accuracy of the original network after training for at most the same number of iterations.” [2]
This concept was contrary to the prior belief that a higher number of parameters in a model results in a more accurate model. The author pointed out that there exists a lottery ticket hypothesis and also proposed an iterative based model to find the sub-networks that can be optimized. The suggested technique is iterative magnitude-based unstructured pruning which is computationally intensive.
PyTorch provides the tools to find the different pruning techniques that agree on what subnetwork is a winning ticket. However, it was found that different winning lottery tickets were found by different pruning techniques when applied using PyTorch. This means there is one lottery ticket that is better than others. The latest research has shown that lottery ticket-style weight rewinding, coupled with unstructured pruning, gives rise to connectivity patterns similar to structured pruning.
The next question is, are these winning lottery tickets transferable from one task to another? Yes, these winning lottery tickets can be transferred from one task, trained from the scratch for another task within the same domain thus avoiding the expensive sourcing of iterative pruning technique.
Moreover, it was also found that the intersection of lottery tickets is itself a lottery ticket. This task can be worked in parallel contrary to the sequential iterative pruning method.
Most of the researches related to pruning in the literature assess the compression method viability in terms of the tradeoff of the total accuracy. They rarely investigate any drop in accuracy in terms of classes which may affect the fairness in the sparse model. The latest research has tested the class accuracy by introducing a class accuracy hypothesis based on the linear model.
Data compression or pruning is highly related to building an AI that is more efficient, more responsible, more private, and more ubiquitous. Automatic identification of lucky sub-networks that can be trained for higher performance. Delivering on shared, widespread computational benefits of sparsity coupled with accessible hardware solutions.
[1] A. See, M.-T. Luong, and C. D. Manning, “Compression of neural machine translation models via pruning,” arXiv Prepr. arXiv1606.09274, 2016.
[2] J. Frankle and M. Carbin, “The lottery ticket hypothesis: Finding sparse, trainable neural networks,” 7th Int. Conf. Learn. Represent. ICLR 2019, 2019.









