Zero-shot object detection (ZSD) is the task of object detection where no labeled training data is available for some target object classes. For example, there are times we'd like to detect objects that are hard to find in the class list of pre-trained models. Also, getting enough labeled is a daunting task and often requires expensive human labor; therefore, ZSD can save time and money.
We employ a zero-shot detection algorithm based on OpenAI's CLIP embeddings, requiring only the target classes' text descriptions. The algorithm works by extracting the image's visual embeddings of hundreds of regions of interest (ROI) and matching them with the target class's text embedding, as shown in Figure 1. If the distance between visual and text embeddings is less than a dynamic threshold, we decide that the concept represented by the text is present in the image. The dynamic threshold is computed by the relative distance between the whole image and the ROI embeddings. The choice of prompted texts strongly affects the accuracy of the outcome and needs further engineering if one is not satisfied with the prediction results by changing, adding, or removing words. One can also take the average of the multiple text embeddings as the prompt. For example, assume one likes to detect the wheels of bicycles. One prompt can be "bike wheel" but also, by seeing the "bike spokes" we can detect the bike wheel. So instead, we can take the average of the embeddings of these two text prompts to include both "bike wheel" and "bike spokes" textual information.
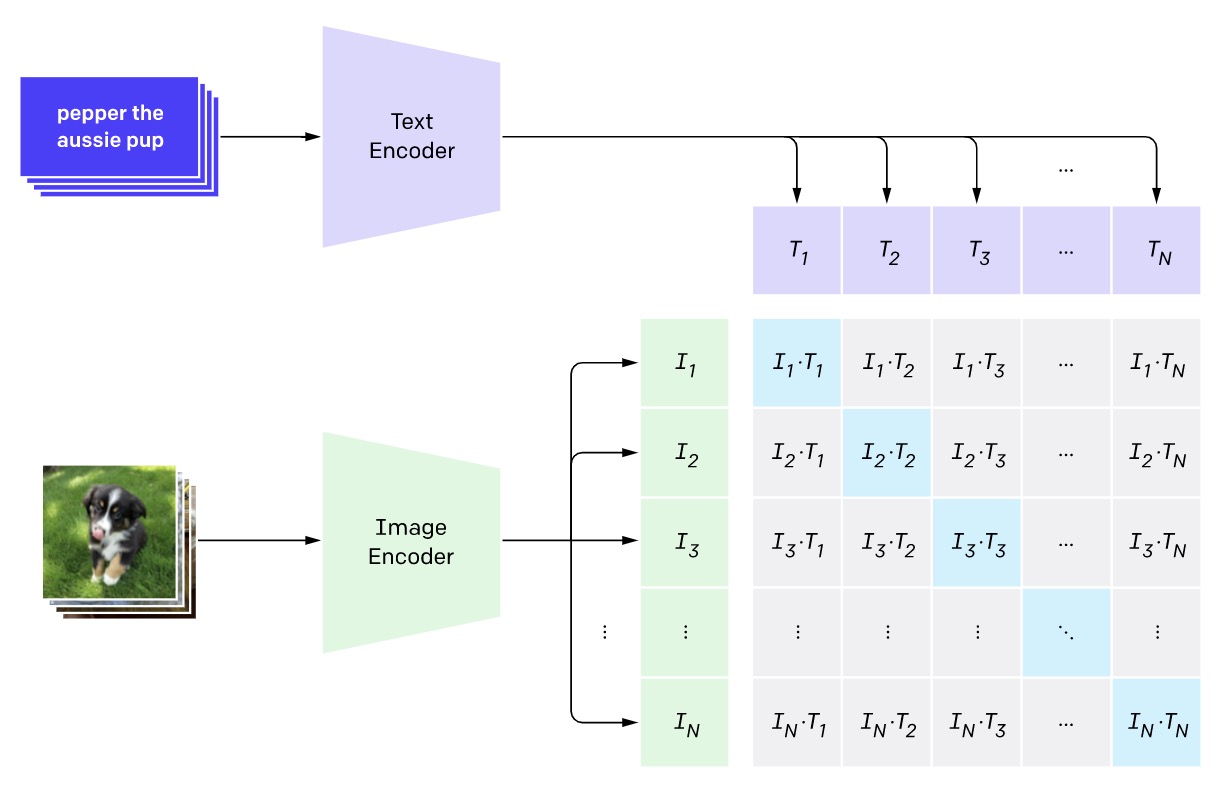 Figure 1. Image from the original blog from OpenAI. The CLIP embeddings model was trained by making the model predict which text matched with each image based on the similarity of their embeddings.
Figure 1. Image from the original blog from OpenAI. The CLIP embeddings model was trained by making the model predict which text matched with each image based on the similarity of their embeddings.
We evaluate the effectiveness of the ZSD on three tasks. The first task is detecting "jumping cats" and "sitting cats". There are many cat datasets, but it's probably hard to find a labeled dataset with "jumping cat" and "sitting cat" as their explicit labels. So we'll show how ZSD can help to accurately find jumping and sitting cats in images! The second task is interesting for real estate agents to detect apartments and houses. The last one is about detecting discount banners in the shops. The tasks are designed so that we can show the capabilities of ZSD in scenarios where gathering labeled data, especially for detection tasks, is expensive.
Task 1: Jumping Cat vs Sitting Cat
We’d like to detect the cats in a jumping posture. So, we prompt the model with “jumping cat” and these are the results:

But what happens if we prompt the model with “sitting cat”? Let’s see:

Task 2: House vs Apartment
Suppose a real estate agent likes to filter or classify the images of homes into two classes of houses or apartments.
Results of prompting the model with “house”:

Results of prompting the model with “apartment”:

Task 3: Discount Banner Detection
Suppose we’d like to detect the discounted sales banners in the streets. We prompt the model with “discount banners” as the target class we are interested in. We evaluated this task over the COCO’s test split, and there were zero false positives. The following are the true positive examples:

Now let’s analyze the behavior of the model with challenging inputs. For the following inputs, the model detects nothing when prompted with “discount banners” or “discounted sales” as expected but detects the banners when prompted with “banners”:
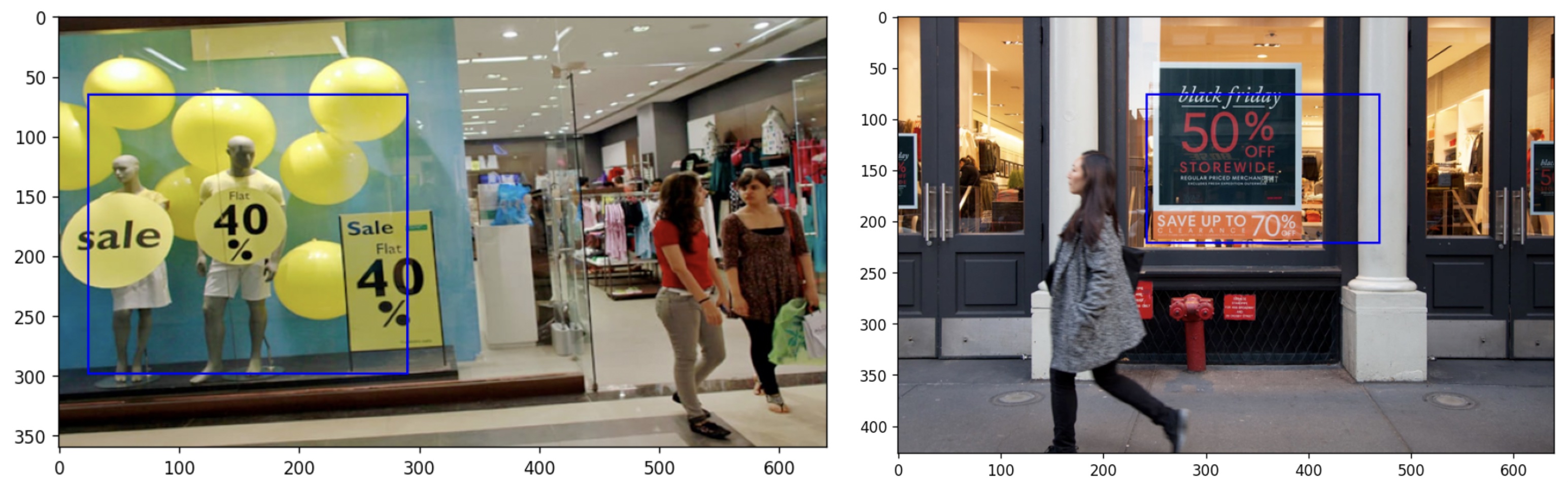
Now let’s analyze the behavior of the model with challenging inputs. For the following inputs, the model detects nothing when prompted with “discount banners” or “discounted sales” as expected but detects the banners when prompted with “banners”:

In summary, the results of the zero-shot object detection using CLIP, especially the low FP rate look surprisingly good. We are actively developing some BE features to support CLIP and zero shot learnings.
References:
[1] https://github.com/shonenkov/CLIP-ODS






