

Deploy in minutes. Inference in milliseconds.
Get from upload to live inference in minutes. Clarifai handles scaling, uptime, and optimization—so you spend time building features, not debugging infrastructure.
Ultra low latency
Cold starts and lag ruin real-time applications. Clarifai delivers sub-300ms time-to-first-token and consistently low latency, even under heavy load—so your AI always feels instant.

Unrivaled token throughput
While other platforms throttle users when traffic surges, Clarifai sustains massive concurrency with unmatched throughput—keeping your apps fast, reliable, and ready to scale.

No downtime, no disruption
While frontier model providers stumble with outages and instability, Clarifai delivers 99.999% reliability. Your models stay online, responsive, and production-ready—no matter the load.

Complexity
Docs that Get You Building
From quickstarts to advanced guides, our documentation helps you move fast. Explore code snippets, setup tutorials, and best practices for deploying, scaling, and securing your models—all in one place.
Visit docs.clarifai.com

The models you trust, optimized for speed.
Every model we host is benchmarked and deployed with the best available framework—whether vLLM, SGLang, or beyond. Run open-source, proprietary, or custom models on infrastructure tuned for maximum performance and reliability.

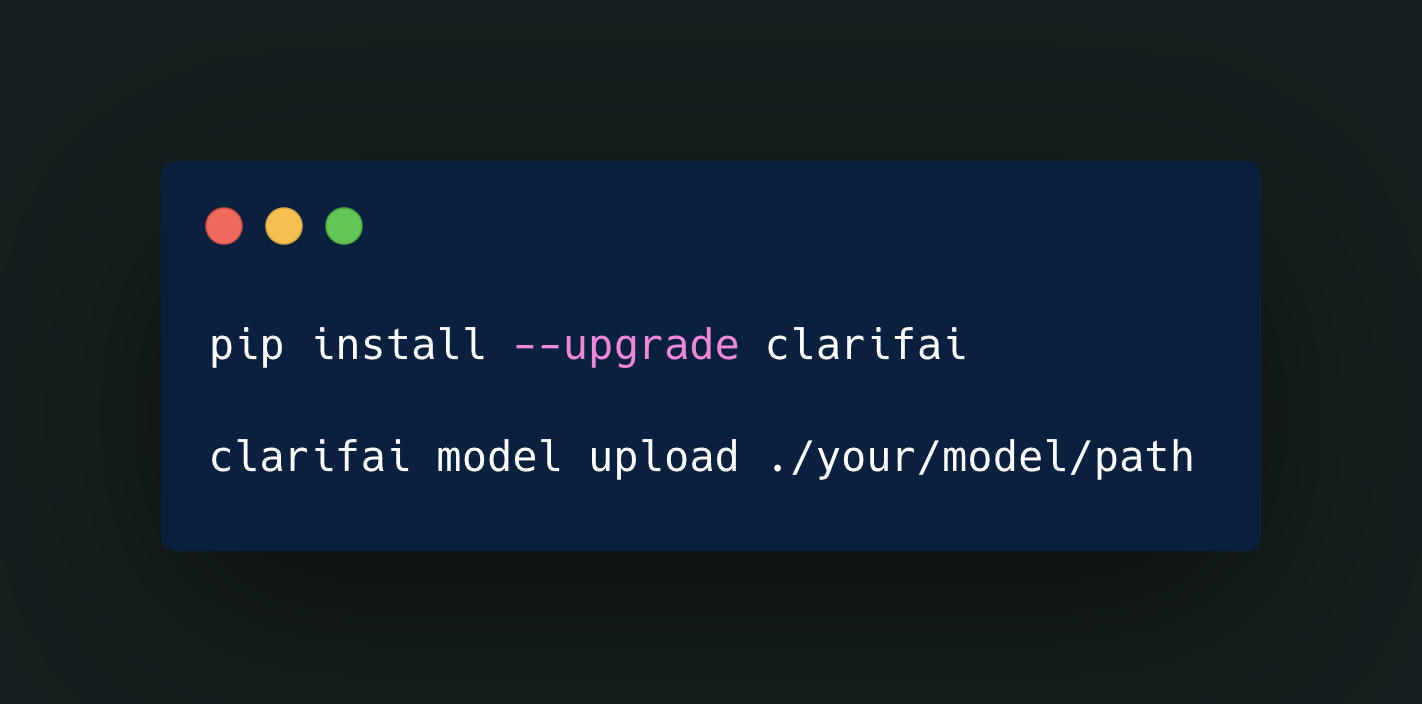
Upload Your Own Model
Get lightning-fast inference for your custom AI models. Deploy in minutes with no infrastructure to manage.

GPT-OSS-120b
OpenAI's most powerful open-weight model, with exceptional instruction following, tool use, and reasoning.

DeepSeek-R1-0528-Quen3-8B
Improves reasoning and logic hrough better computation and optimization. Nears the performance of OpenAI and Gemini models.

Llama-3_2-3B-Instruct
A multilingual model by Meta optimized for dialogue and summarization. Uses SFT and RLHF for better alignment and performance.

Qwen3-Coder-30B-A3B-Instruct
A high-performing, efficient model with strong agentic coding abilities, long-context support, and broad platform compatibility.

MiniCPM4-8B
The MiniCPM4 series are efficient LLMs optimized for end-side devices, achieved through innovations in architecture, data, training, and inference.

Devstral-Small-2505-unsloth-bnb-4bit
An agentic LLM developed by Mistral AI and All Hands AI to explore codebases, edit multiple files, and support engineering agents.

Claude-Sonnet-4
State-of-the-art LLM from Anthropic that supports multimodal inputs and can generate high-quality, context-aware text completions, summaries, and more.

Phi-4-Reasoning-Plus
Microsoft's open-weight reasoning model trained using supervised fine-turning on a dataset of chain-of-thought traces and reinforcement learning.

Explore Clarifai Today
Ship fast and scale without fear. With Clarifai, your models stay online, responsive, and production-ready—no matter the load.
