

Automated Data Labeling
Automate Your Data Engine
Streamline your labeling tasks with AI-powered automation and efficient human review workflows.

Build AI datasets with confidence
Clarifai was built to simplify how developers and teams create, share, and run AI at scale.
Ingest individual inputs or archives
Auto label as you ingest data with customizable ontologies. Complete support for imagery, video and text formats.
Index your inputs for search
Auto-index your input data using customizable embedding vectors for semantic similarity search and easier dataset management.
Manage datasets for labeling
Create, version and manage your datasets for data labeling, model training and evaluation. Export your data via SDK.
Faster supervised labeling with AI Assist
Standardize across popular models and frameworks to foster collaborate and innovate
Resource Monitoring
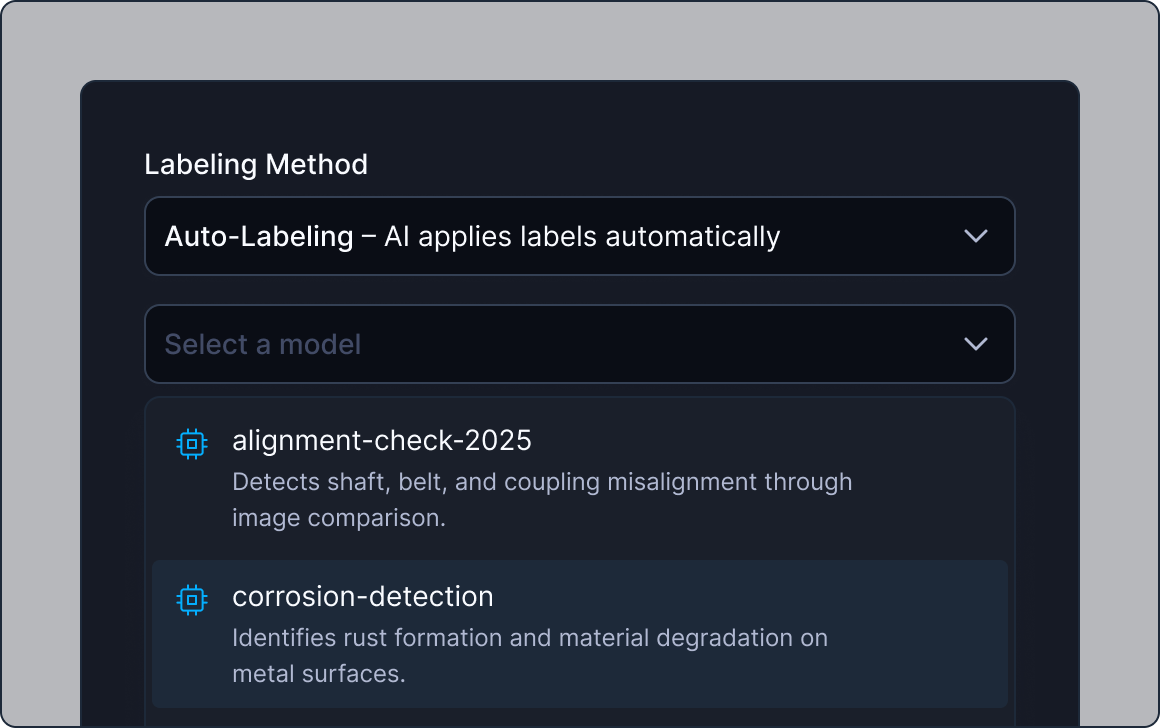
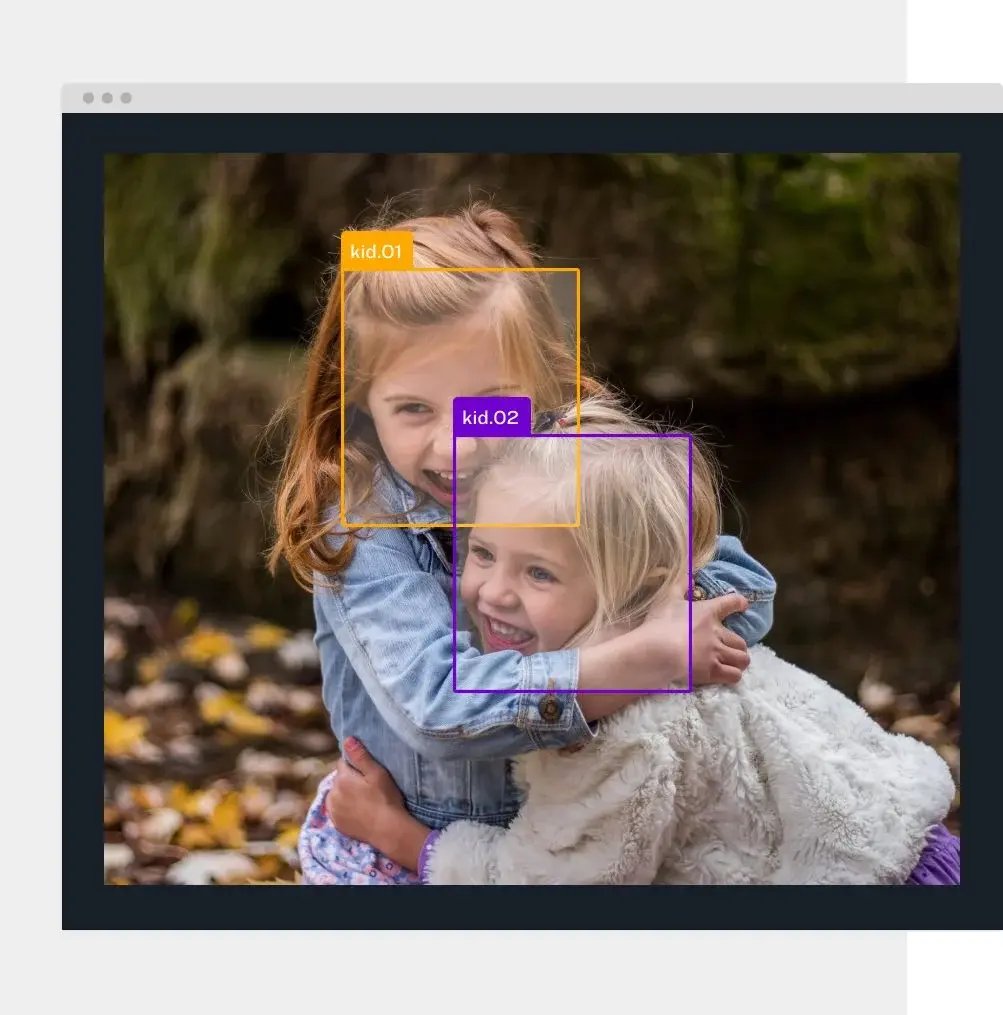
Automate your data labeling
Automated labeling with AI models including uploaded or custom-trained to your task
Complexity
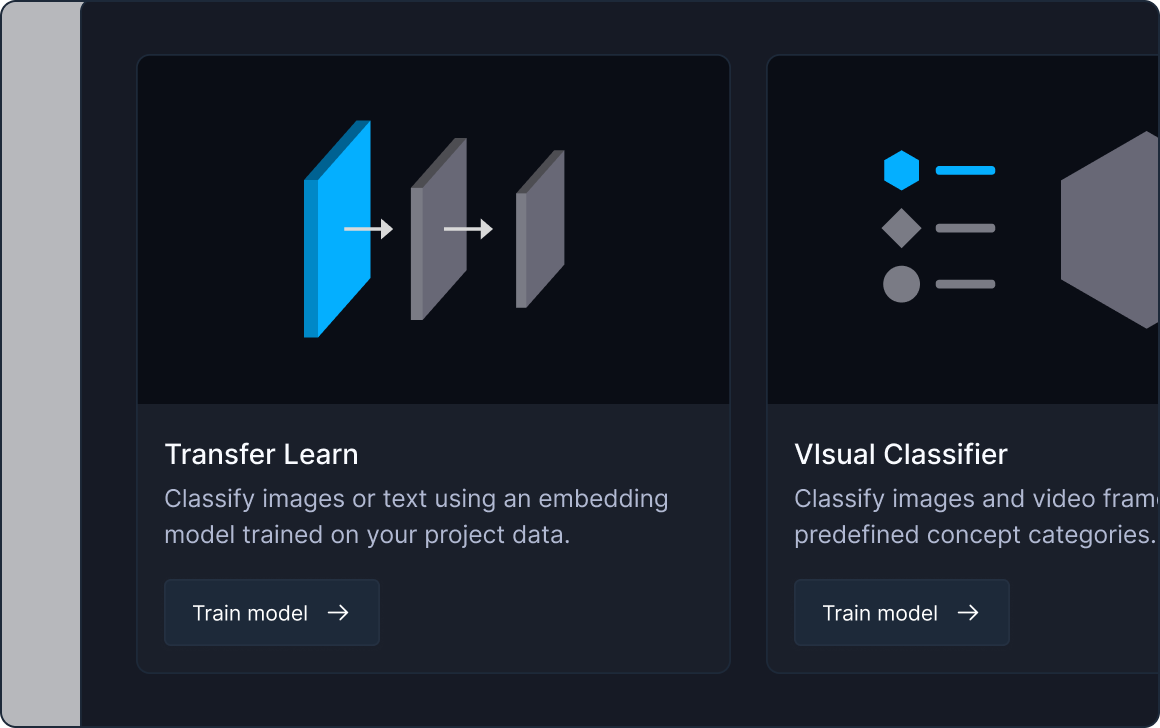
One-click custom model training
Standardize across popular models and frameworks to foster collaborate and innovate
Complexity
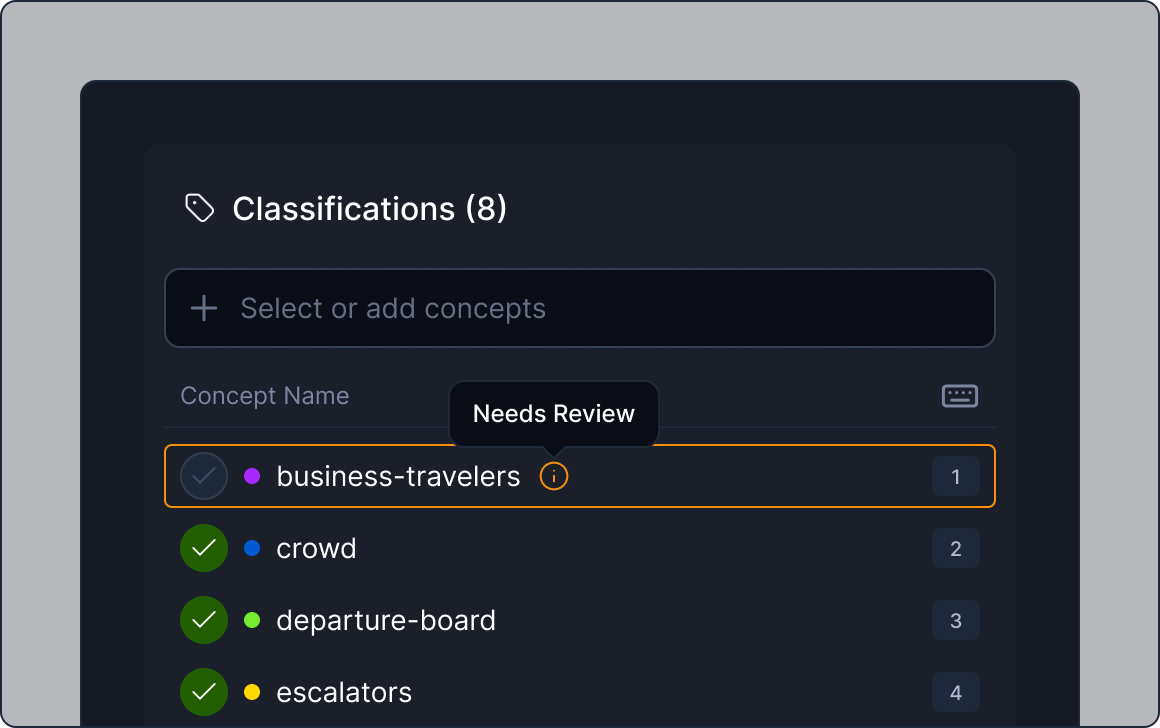
Powerful semi-supervised auto annotation
Standardize across popular models and frameworks to foster collaborate and innovate
Complexity
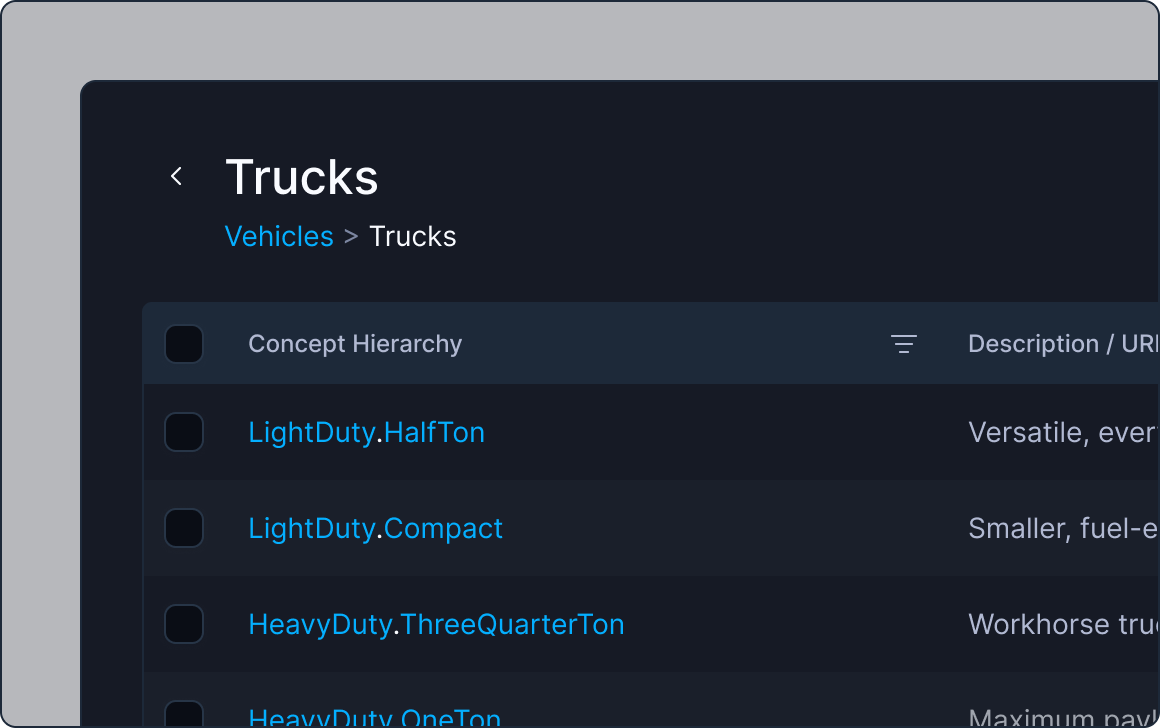
Support advanced hierarchical ontologies
Customizable labeling ontologies, including advanced hierarchical ontologies for complex use cases.
Reduction in per-label time for humans
“AI Assist and Auto Annotation helped us accelerate our model development using the same techniques that the best Silicon Valley companies are using.”




Integrate with your existing AI stack
Scale your AI with confidence
Clarifai was built to simplify how developers and
teams create, share, and run AI at scale

Establish an AI Operating Model and get out of prototype and into production

Build a RAG system in 4 lines of code

Make sense of the jargon around Generative AI with our glossary
Build your next AI app, test and tune popular LLMs models, and much more.

