Artificial intelligence has moved beyond experimentation — it’s powering search engines, recommender systems, financial models, and autonomous vehicles. Yet one of the biggest hurdles standing between promising prototypes and production impact is deploying models safely and reliably. Recent research notes that while 78 percent of organizations have adopted AI, only about 1 percent have achieved full maturity. That maturity requires scalable infrastructure, sub‑second response times, monitoring, and the ability to roll back models when things go wrong. With the landscape evolving rapidly, this article offers a use‑case driven compass to selecting the right deployment strategy for your AI models. It draws on industry expertise, research papers, and trending conversations across the web while highlighting where Clarifai’s products naturally fit.
If you want the short answer: There is no single best strategy. Deployment techniques such as shadow testing, canary releases, blue‑green rollouts, rolling updates, multi‑armed bandits, serverless inference, federated learning, and agentic AI orchestration all have their place. The right approach depends on the use case, the risk tolerance, and the need for compliance. For example:
We'll unpack each scenario in detail, provide actionable guidance, and share expert insights under every section.
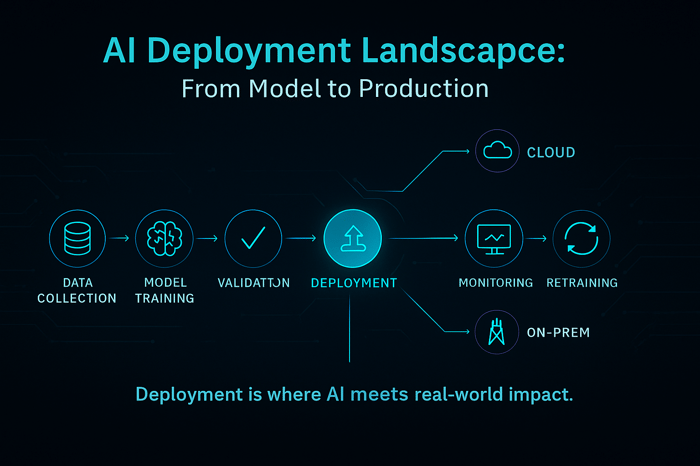
Moving from a model on a laptop to a production service is challenging for three reasons:
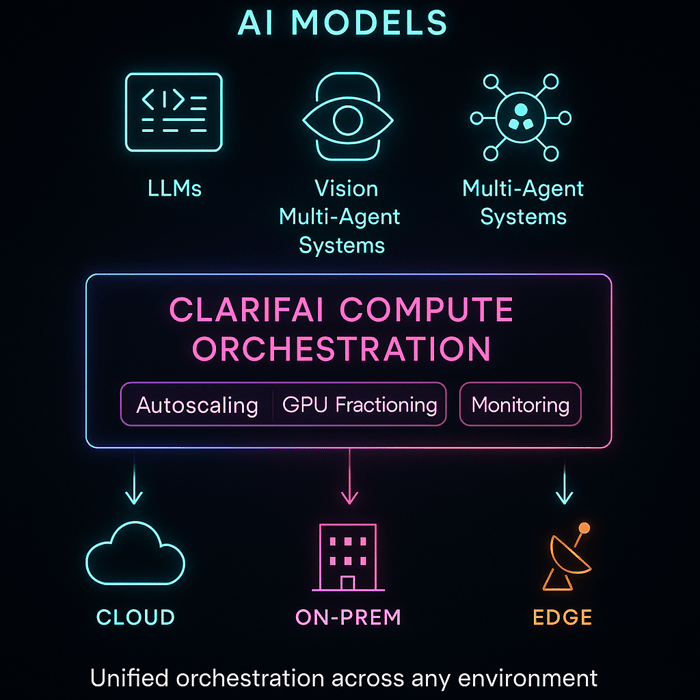
Clarifai's perspective: As a leader in AI, Clarifai sees these challenges daily. The Clarifai platform offers compute orchestration to manage models across GPU clusters, on‑prem and cloud inference options, and local runners for edge deployments. These capabilities ensure models run where they are needed most, with robust observability and rollback features built in.
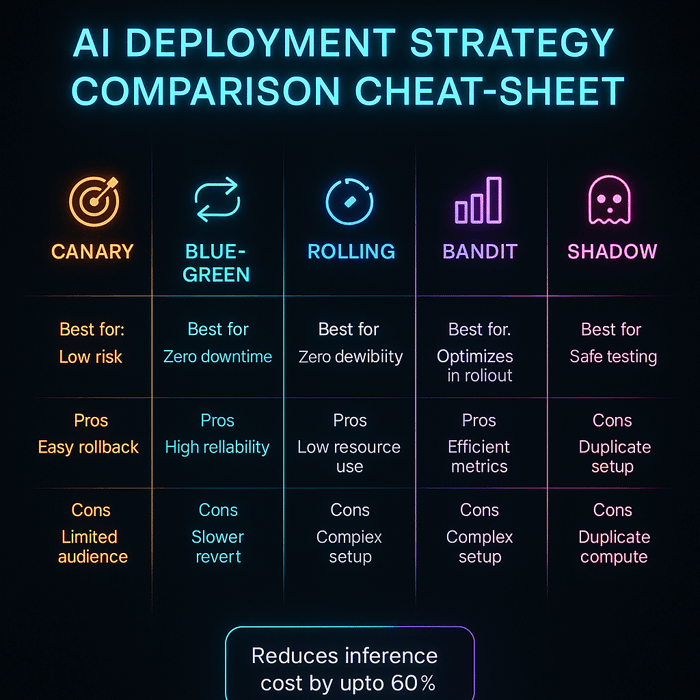
Shadow testing (sometimes called silent deployment or dark launch) is a technique where the new model receives a copy of live traffic but its outputs are not shown to users. The system logs predictions and compares them to the current model’s outputs to measure differences and potential improvements. Shadow testing is ideal when you want to evaluate model performance in real conditions without risking user experience.
Many teams deploy models after only offline metrics or synthetic tests. Shadow testing reveals real‑world behavior: unexpected latency spikes, distribution shifts, or failures. It allows you to collect production data, detect bias, and calibrate risk thresholds before serving the model. You can run shadow tests for a fixed period (e.g., 48 hours) and analyze metrics across different user segments.
Imagine you are deploying a new computer‑vision model to detect product defects on a manufacturing line. You set up a shadow pipeline: every image captured goes to both the current model and the new one. The new model’s predictions are logged, but the system still uses the existing model to control machinery. After a week, you find that the new model catches defects earlier but occasionally misclassifies rare patterns. You adjust the threshold and only then plan to roll out.
After shadow testing, the next step for real‑time applications is often a canary release. This approach sends a small portion of traffic – such as 1 percent – to the new model while the majority continues to use the stable version. If metrics remain within predefined bounds (latency, error rate, conversion, fairness), traffic gradually ramps up.
Consider a customer support chatbot that answers product questions. A new dialogue model promises better responses but might hallucinate. You release it as a canary to 2 percent of users with guardrails: if the model cannot answer confidently, it transfers to a human. Over a week, you track average customer satisfaction and chat duration. When satisfaction improves and hallucinations remain rare, you ramp up traffic gradually.
In contexts where you are comparing multiple models or strategies and want to optimize during rollout, multi‑armed bandits can outperform static A/B tests. Bandit algorithms dynamically allocate more traffic to better performers and reduce exploration as they gain confidence.
A/B tests allocate fixed percentages of traffic to each variant until statistically significant results emerge. Bandits, however, adapt over time. They balance exploration and exploitation: ensuring that all options are tried but focusing on those that perform well. This results in higher cumulative reward, but the statistical analysis is more complex.
Suppose your e‑commerce platform uses an AI model to recommend products. You have three candidate models: Model A, B, and C. Instead of splitting traffic evenly, you employ a Thompson sampling bandit. Initially, traffic is split roughly equally. After a day, Model B shows higher click‑through rates, so it receives more traffic while Models A and C receive less but are still explored. Over time, Model B is clearly the winner, and the bandit automatically shifts most traffic to it.
When downtime is unacceptable (for example, in payment gateways, healthcare diagnostics, and online banking), the blue‑green strategy is often preferred. In this approach, you maintain two environments: Blue (current production) and Green (the new version). Traffic can be switched instantly from blue to green and back.
Industries like healthcare, finance, and insurance face stringent regulatory requirements. They must ensure models are fair, explainable, and auditable. Deployment strategies here often involve extended shadow or silent testing, human oversight, and careful gating.
Suppose a loan underwriting model is being updated. The team first deploys it silently and logs predictions for thousands of applications. They compare outcomes by gender and ethnicity to ensure the new model does not inadvertently disadvantage any group. A compliance officer reviews the results and only then approves a canary rollout. The underwriting system still requires a human credit officer to sign off on any decision, providing an extra layer of oversight.
Domains like fraud detection, content moderation, and finance see rapid changes in data distribution. Concept drift can degrade model performance quickly if not addressed. Rolling updates and champion‑challenger frameworks help handle continuous improvement.
Not all models need millisecond responses. Many enterprises rely on batch or offline scoring for tasks like overnight risk scoring, recommendation embedding updates, and periodic forecasting. For these scenarios, deployment strategies focus on accuracy, throughput, and determinism rather than latency.
As billions of devices come online, Edge AI has become a crucial deployment scenario. Edge AI moves computation closer to the data source, reducing latency and bandwidth consumption and improving privacy. Rather than sending all data to the cloud, devices like sensors, smartphones, and autonomous vehicles perform inference locally.
When training models across distributed devices or institutions, federated learning enables collaboration without moving raw data. Each participant trains locally on its own data and shares only model updates (gradients or weights). The central server aggregates these updates to form a global model.
Benefits: Federated learning aligns with privacy‑enhancing technologies and reduces the risk of data breaches. It keeps data under the control of each organization or user and promotes accountability and auditability.
Challenges: FL can still leak information through model updates. Attackers may attempt membership inference or exploit distributed training vulnerabilities. Teams must implement secure aggregation, differential privacy, and robust communication protocols.
Imagine a hospital consortium training a model to predict sepsis. Due to privacy laws, patient data cannot leave the hospital. Each hospital runs training locally and shares only encrypted gradients. The central server aggregates these updates to improve the model. Over time, all hospitals benefit from a shared model without violating privacy.
Software‑as‑a‑service platforms often host many customer workloads. Each tenant might require different models, data isolation, and release schedules. To avoid one customer’s model affecting another’s performance, platforms adopt cell‑based rollouts: isolating tenants into independent "cells" and rolling out updates cell by cell.
RAG is a hybrid architecture that combines language models with external knowledge retrieval to produce grounded answers. According to recent reports, the RAG market reached $1.85 billion in 2024 and is growing at 49 % CAGR. This surge reflects demand for models that can cite sources and reduce hallucination risks.
How RAG works: The pipeline comprises three components: a retriever that fetches relevant documents, a ranker that orders them, and a generator (LLM) that synthesizes the final answer using the retrieved documents. The retriever may use dense vectors (e.g., BERT embeddings), sparse methods (e.g., BM25), or hybrid approaches. The ranker is often a cross‑encoder that provides deeper relevance scoring. The generator uses the top documents to produce the answer.
Benefits: RAG systems can cite sources, comply with regulations, and avoid expensive fine‑tuning. They reduce hallucinations by grounding answers in real data. Enterprises use RAG to build chatbots that answer from corporate knowledge bases, assistants for complex domains, and multimodal assistants that retrieve both text and images.
Agentic AI refers to systems where AI agents make decisions, plan tasks, and act autonomously in the real world. These agents might write code, schedule meetings, or negotiate with other agents. Their promise is enormous but so are the risks.
McKinsey analysts emphasize that success with agentic AI isn’t about the agent itself but about reimagining the workflow. Companies should map out the end‑to‑end process, identify where agents can add value, and ensure people remain central to decision‑making. The most common pitfalls include building flashy agents that do little to improve real work, and failing to provide learning loops that let agents adapt over time.
High‑variance, low‑standardization tasks benefit from agents: e.g., summarizing complex legal documents, coordinating multi‑step workflows, or orchestrating multiple tools. For simple rule‑based tasks (data entry), rule‑based automation or predictive models suffice. Use this guideline to avoid deploying agents where they add unnecessary complexity.
Agentic AI introduces new vulnerabilities. McKinsey notes that agentic systems present attack surfaces akin to digital insiders: they can make decisions without human oversight, potentially causing harm if compromised. Risks include chained vulnerabilities (errors cascade across multiple agents), synthetic identity attacks, and data leakage. Organizations must set up risk assessments, safelists for tools, identity management, and continuous monitoring.
Imagine a multi‑agent system that helps engineers troubleshoot software incidents. A monitoring agent detects anomalies and triggers an analysis agent to query logs. If the issue is code-related, a code assistant agent suggests fixes and a deployment agent rolls them out under human approval. Each agent has defined roles and must log actions. Governance policies limit the resources each agent can modify.
In traditional AI deployment, teams manage GPU clusters, container orchestration, load balancing, and auto‑scaling. This overhead can be substantial. Serverless inference offers a paradigm shift: the cloud provider handles resource provisioning, scaling, and management, so you pay only for what you use. A model can process a million predictions during a peak event and scale down to a handful of requests on a quiet day, with zero idle cost.
Features: Serverless inference includes automatic scaling from zero to thousands of concurrent executions, pay‑per‑request pricing, high availability, and near‑instant deployment. New services like serverless GPUs (announced by major cloud providers) allow GPU‑accelerated inference without infrastructure management.
Use cases: Rapid experiments, unpredictable workloads, prototypes, and cost‑sensitive applications. It also suits teams without dedicated DevOps expertise.
Limitations: Cold start latency can be higher; long‑running models may not fit the pricing model. Also, vendor lock‑in is a concern. You may have limited control over environment customization.
According to industry forecasts, more companies are running custom AI models on‑premise due to open‑source models and compliance requirements. On‑premise deployments give full control over data, hardware, and network security. They allow for air‑gapped systems when regulatory mandates require that data never leaves the premises.
Hybrid strategies combine both: run sensitive components on‑prem and scale out inference to the cloud when needed. For example, a bank might keep its risk models on‑prem but burst to cloud GPUs for large scale inference.
A retail analytics company processes millions of in-store camera feeds to detect stockouts and shopper behavior. They run a baseline model on serverless GPUs to handle spikes during peak shopping hours. For stores with strict privacy requirements, they deploy local runners that keep footage on site. Clarifai’s platform orchestrates the models across these environments and manages update rollouts.
There are many strategies to choose from. Here is a simplified framework:
Ask: Is the model user-facing? Does it operate in a regulated domain? How costly is an error? High-risk use cases (medical diagnosis) need conservative rollouts. Low-risk models (content recommendation) can use more aggressive strategies.
Develop a testing plan: gather baseline metrics, define success criteria, and choose monitoring tools. Use CI/CD pipelines and model registries to track versions, metrics, and rollbacks. Automate logging, alerts, and fallbacks.
After deployment, monitor metrics continuously. Observe for drift, bias, or performance degradation. Set up triggers to retrain or roll back. Evaluate business impact and adjust strategies as necessary.
|
Use Case |
Recommended Deployment Strategies |
Why These Work Best |
|
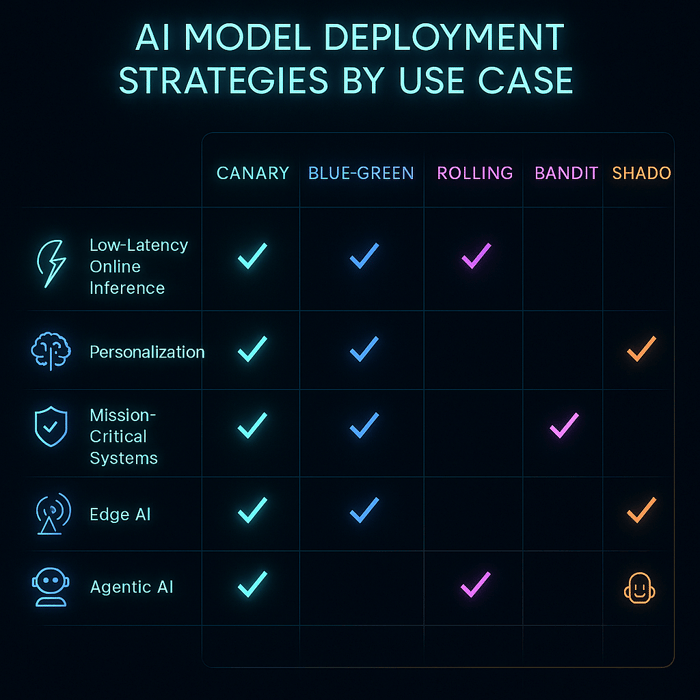
1. Low-Latency Online Inference (e.g., recommender systems, chatbots) |
• Canary Deployment • Shadow/Mirrored Traffic • Cell-Based Rollout |
Gradual rollout under live traffic; ensures no latency regressions; isolates failures to specific user groups. |
|
2. Continuous Experimentation & Personalization (e.g., A/B testing, dynamic UIs) |
• Multi-Armed Bandit (MAB) • Contextual Bandit |
Dynamically allocates traffic to better-performing models; reduces experimentation time and improves online reward. |
|
3. Mission-Critical / Zero-Downtime Systems (e.g., banking, payments) |
• Blue-Green Deployment |
Enables instant rollback; maintains two environments (active + standby) for high availability and safety. |
|
4. Regulated or High-Risk Domains (e.g., healthcare, finance, legal AI) |
• Extended Shadow Launch • Progressive Canary |
Allows full validation before exposure; maintains compliance audit trails; supports phased verification. |
|
5. Drift-Prone Environments (e.g., fraud detection, ad click prediction) |
• Rolling Deployment • Champion-Challenger Setup |
Smooth, periodic updates; challenger model can gradually replace the champion when it consistently outperforms. |
|
6. Batch Scoring / Offline Predictions (e.g., ETL pipelines, catalog enrichment) |
• Recreate Strategy • Blue-Green for Data Pipelines |
Simple deterministic updates; rollback by dataset versioning; low complexity. |
|
7. Edge / On-Device AI (e.g., IoT, autonomous drones, industrial sensors) |
• Phased Rollouts per Device Cohort • Feature Flags / Kill-Switch |
Minimizes risk on hardware variations; allows quick disablement in case of model failure. |
|
8. Multi-Tenant SaaS AI (e.g., enterprise ML platforms) |
• Cell-Based Rollout per Tenant Tier • Blue-Green per Cell |
Ensures tenant isolation; supports gradual rollout across different customer segments. |
|
9. Complex Model Graphs / RAG Pipelines (e.g., retrieval-augmented LLMs) |
• Shadow Entire Graph • Canary at Router Level • Bandit Routing |
Validates interactions between retrieval, generation, and ranking modules; optimizes multi-model performance. |
|
10. Agentic AI Applications (e.g., autonomous AI agents, workflow orchestrators) |
• Shadowed Tool-Calls • Sandboxed Orchestration • Human-in-the-Loop Canary |
Ensures safe rollout of autonomous actions; supports controlled exposure and traceable decision memory. |
|
11. Federated or Privacy-Preserving AI (e.g., healthcare data collaboration) |
• Federated Deployment with On-Device Updates • Secure Aggregation Pipelines |
Enables training and inference without centralizing data; complies with data protection standards. |
|
12. Serverless or Event-Driven Inference (e.g., LLM endpoints, real-time triggers) |
• Serverless Inference (GPU-based) • Autoscaling Containers (Knative / Cloud Run) |
Pay-per-use efficiency; auto-scaling based on demand; great for bursty inference workloads. |
Expert Insight
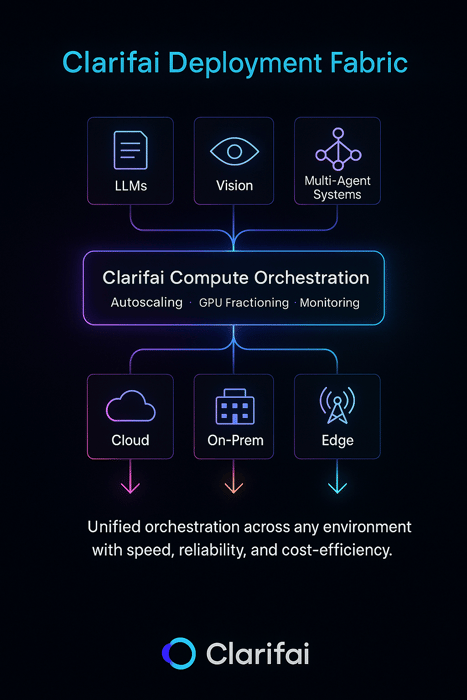
Modern AI deployment isn’t just about putting models into production — it’s about doing it efficiently, reliably, and across any environment. Clarifai’s platform helps teams operationalize the strategies discussed earlier — from canary rollouts to hybrid edge deployments — through a unified, vendor-agnostic infrastructure.
Clarifai’s Compute Orchestration serves as a control plane for model workloads, intelligently managing GPU resources, scaling inference endpoints, and routing traffic across cloud, on-prem, and edge environments.
It’s designed to help teams deploy and iterate faster while maintaining cost transparency and performance guarantees.
Key advantages:
“Our customers can now scale their AI workloads seamlessly — on any infrastructure — while optimizing for cost, reliability, and speed.”
— Matt Zeiler, Founder & CEO, Clarifai
For workloads that demand privacy or ultra-low latency, Clarifai AI Runners extend orchestration to local and edge environments, letting models run directly on internal servers or devices while staying connected to the same orchestration layer.
This enables secure, compliant deployments for enterprises handling sensitive or geographically distributed data.
Together, Compute Orchestration and AI Runners give teams a single deployment fabric — from prototype to production, cloud to edge — making Clarifai not just an inference engine but a deployment strategy enabler.
Canary deployments gradually roll out the new version to a subset of users, monitoring performance and rolling back if needed. Blue-green deployments create two parallel environments; you cut over all traffic at once and can revert instantly by switching back.
Use federated learning when data is distributed across devices or institutions and cannot be centralized due to privacy or regulation. Federated learning enables collaborative training while keeping data localized.
Monitor input feature distributions, prediction distributions, and downstream business metrics over time. Set up alerts if distributions deviate significantly. Tools like Clarifai’s model monitoring or open-source solutions can help.
Agentic AI introduces new vulnerabilities such as synthetic identity attacks, chained errors across agents, and untraceable data leakage. Organizations must implement layered governance, identity management, and simulation testing before connecting agents to real systems.
Serverless inference eliminates the operational burden of managing infrastructure. It scales automatically and charges per request. However, it may introduce latency due to cold starts and can lead to vendor lock-in.
Clarifai provides a full-stack AI platform. You can train, deploy, and monitor models across cloud GPUs, on-prem clusters, local devices, and serverless endpoints. Features like compute orchestration, model registry, role-based access control, and auditable logs support safe and compliant deployments.
Model deployment strategies are not one-size-fits-all. By matching deployment techniques to specific use cases and balancing risk, speed, and cost, organizations can deliver AI reliably and responsibly. From shadow testing to agentic orchestration, each strategy requires careful planning, monitoring, and governance. Emerging trends like serverless inference, federated learning, RAG, and agentic AI open new possibilities but also demand new safeguards. With the right frameworks and tools—and with platforms like Clarifai offering compute orchestration and scalable inference across hybrid environments—enterprises can turn AI prototypes into production systems that truly make a difference.