

With Clarifai's new Data Mode in Clarifai Portal, we've made it easy for anyone to load their data into the Clarifai platform so that they can label, train, search and predict. Data Mode is available in Portal and comes with a ton of useful features for uploading images, videos and text.
Data Mode is the best place to start for most users, but what happens when you are working with extremely large datasets (ones where you might not want to have to keep a bowser window open), or you want to integrate data loading directly within your application pipeline? This is where the Clarifai API comes in. Let's take a look at Data Mode, and then take a look at how you can build your own data ingestion pipeline with the Clarifai API.
Introducing Data Mode
Data mode makes data ingestion a snap with features that will be familiar to anyone who has ever uploaded an image, video, or text to the web. You can upload images from a URL if the images are already hosted online, or directly from your computer. To get started with Data Mode visit Portal, and click the data tab on the lefthand side of the screen.
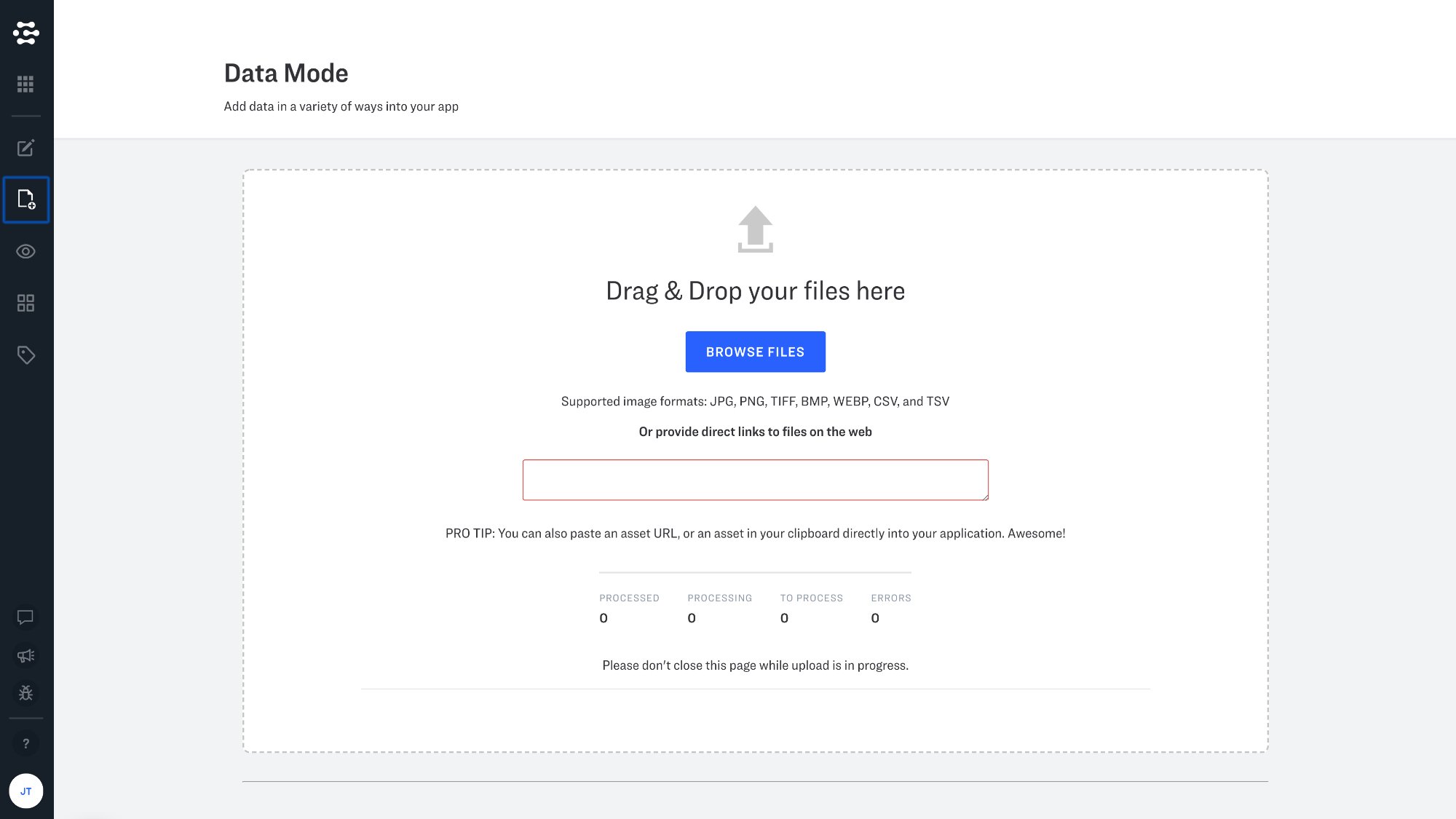
Upload CSV and TSV files in Data Mode
CSV (comma separated values) and/or TSV (table separated values) files can be a convenient way to work with multiple inputs, since these files can be easily managed by your favorite spreadsheet editor. The following API example parses .csv files, and Portal supports CSV and TSV file uploads as well. Please see our documentation for more details on how to set up your CSV and TSV files for ingestion via Data Mode.
Integration with the Clarifai API
When you are working with very large amounts of data, or want to integrate data ingestion directly within your application, the Clarifai API is here to help.
Let's take a look at how data ingestion might be configured using our Python gRPC client when uploading images. In this blog post we will take a look at a script developed by one of our own applied machine learning engineers. This script is designed to upload images, their associated concepts and metadata. The details of your implementation may be different of course, but we hope that this script can help address common issues and help to jumpstart your own integration.
Dependencies
Lets begin with the imports that we are using in this example. Here you will see argparse is being used so that we can pass arguments through the command line, json is used to decode your optional metadata blob, pandas is being used to help us load and manage our .csv file as a DataFrame for convenient batching, Stuct is used to translate dictionaries into a format readable by Google protobufs, and ThreadPoolExecutor helps us handle multithreading. tqdm provides us with an optional status bar, so that we can keep track of how our data uploads are going. The rest is standard Clarifai initialization code that you can learn more about here.
Functions
Instead of iterating through the DataFrame generated by our .csv file line-by-line, we are going to break it up into batches or "chunks". This is where the chunker function helps us out.
Next up, lets begin to parse our .csv file. We begin by loading the .csv file as a DataFrame, replacing any empty values with empty strings (otherwise the DataFrame would treat these values as NANs, a less convenient option in our case), and then pulling up a list of column names from the .csv file.
We then check to see if a given column names exists, and separate any values by vertical "pipe" or "bar" and then turn these items into a list. If values are detected in the metadata column, these values will be loaded as a Python dictionary, using json.loads.
Now we "process and upload" our chunk, iterating through our batches and processing the individual lines of our .csv file. We create an empty inputs list and go through each line in the list and convert it into an input proto - this is the format we need to create inputs to send into our API. Each individual row is passed through the process_one_line function, and converted into their respective input proto. Note that the value of "1" is used to denote positive concepts and the value of "0" is used to denote negative concepts.
The input_proto defines the input itself and passes in the URL of the image in question. Finally we make our request call to the API and pass in the list of input protos that we have created. Our authentication metadata is required here. Finally we return a response.status.code so that we can know if our request has been successful.
The main function starts by setting up the various arguments that we want to be able to pass in with argparse. Next we construct the stub that will allow us call the API endpoints that we will be using. We then read in our .csv file as a DataFrame through our initial_csv_wrangling function.
Finally we create an empty list called threads, we insert our optional tqdm function so that we can see a progress bar as our job completes, and then we create a thread to iterate trough our "chunks" in batch sizes of 32. We then read in the response from our PostInputsRequest call, add one tick to our progress bar, and capture the main error cases that we want to be looking out for.
Please visit this GitHub repository to view the full code for this and other helper scripts.


