
Databricks, the data and AI company, combines the best of data warehouses and data lakes to offer an open and unified platform for data and AI. And the Clarifai and Databricks partnership now enables our joint customers to gain insights from their visual and textual data at scale.
A major bottleneck for many AI projects or applications is having a sufficient volume of, a sufficient quality of, and sufficiently labeled data. Deriving value from unstructured data becomes a whole lot simpler when you can annotate directly where you already trust your enterprise data to. Why build data pipelines and use multiple tools when a single one will suffice?
ClarifaiPySpark SDK empowers Databricks users to create and initiate machine learning workflows, perform data annotations, and access other features. Hence, it resolves the complexities linked to cross-platform data access, annotation processes, and the effective extraction of insights from large-scale visual and textual datasets.
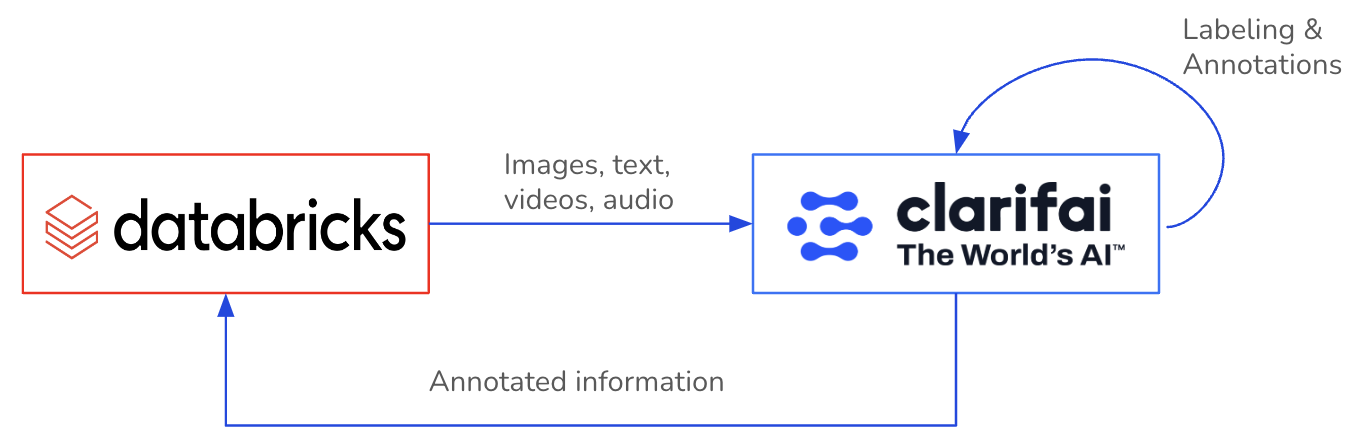
In this blog, we will explore the ClarifaiPySpark SDK to enable a connection between Clarifai and Databricks, facilitating bi-directional import and export of data while enabling the retrieval of data annotations from your Clarifai applications to Databricks.
Install ClarifaiPyspark SDK in your Databricks workspace (in a notebook) with the below command:
Begin by obtaining your PAT token from the instructions here and configuring it as a Databricks secret. Signup here.
In Clarifai, applications serve as the fundamental unit for developing projects. They house your data, annotations, models, workflows, predictions, and searches. Feel free to create multiple applications and modify or remove them as needed.
Seamlessly integrating your Clarifai App with Databricks through ClarifaiPyspark SDK is an easy process. The SDK can be utilized within your Ipython notebook or python script files in your Databricks workspace.
Create a ClarifaiPyspark client object to establish a connection with your Clarifai App.
Obtain the dataset object for the specific dataset within your App. If it doesn't exist, this will automatically create a new dataset within the App.
In this initial version of the SDK, we've focused on a scenario where users can seamlessly transfer their dataset from Databricks volumes or an S3 bucket to their Clarifai App. After annotating the data within the App, users can export both the data and its annotations from the App, allowing them to store it in their preferred format. Now, let's explore the technical aspects of accomplishing this.
The ClarifaiPyspark SDK offers diverse methods for ingesting/uploading your dataset from both Databricks Volumes and AWS S3 buckets, providing you the freedom to select the most suitable approach. Let's explore how you can ingest data into your Clarifai app using these methods.
If your dataset images or text files are stored within a Databricks volume, you can directly upload the data files from the volume to your Clarifai App. Please ensure that the folder solely contains images/text files. If the folder name serves as the label for all the images within it, you can set the labels parameter to True.
You can populate the dataset from a CSV that must include these essential columns: 'inputid' and 'input'. Additional supported columns in the CSV are 'concepts', 'metadata', and 'geopoints'. The 'input' column can contain a file URL or path, or it can have raw text. If the 'concepts' column exists in the CSV, set 'labels=True'. You also have the option to use a CSV file directly from your AWS S3 bucket. Simply specify the 'source' parameter as 's3' in such cases.
You can employ a delta table to populate a dataset in your App. The table should include these essential columns: 'inputid' and 'input'. Furthermore, the delta table supports additional columns such as 'concepts,' 'metadata,' and 'geopoints.' The 'input' column is versatile, allowing it to contain file URLs or paths, as well as raw text. If the 'concepts' column is present in the table, remember to enable the 'labels' parameter by setting it to 'True.' You also have the choice to use a delta table stored within your AWS S3 bucket by providing its S3 path.
You can upload a dataset from a dataframe that should include these required columns: 'inputid' and 'input'. Additionally, the dataframe supports other columns such as 'concepts', 'metadata', and 'geopoints'. The 'input' column can accommodate file URLs or paths, or it can hold raw text. If the dataframe contains the 'concepts' column, set 'labels=True'.
In case your dataset is stored in an alternative format or requires preprocessing, you have the flexibility to supply a custom dataloader class object. You can explore various dataloader examples for reference here. The required files & folders for dataloader should be stored in Databricks volume storage.
The ClarifaiPyspark SDK provides various ways to access your dataset from the Clarifai App to a Databricks volume. Whether you're interested in retrieving input details or downloading input files into your volume storage, we'll walk you through the process.
To access information about the data files within your Clarifai App's dataset, you can use the following function which returns a JSON response. You may use the 'input_type' parameter for retrieving the details for a specific type of data file such as 'image', 'video', 'audio', or 'text'.
You can also obtain input details in a structured dataframe format, featuring columns such as 'input_id,' 'image_url/text_url,' 'image_info/text_info,' 'input_created_at,' and 'input_modified_at.' Be sure to specify the 'input_type' when using this function. Please note that the the JSON response might include additional attributes.
With this function, you can directly download the image/text files from your Clarifai App's dataset to your Databricks volume. You'll need to specify the storage path in the volume for the download and use the response obtained from list_inputs() as the parameter.
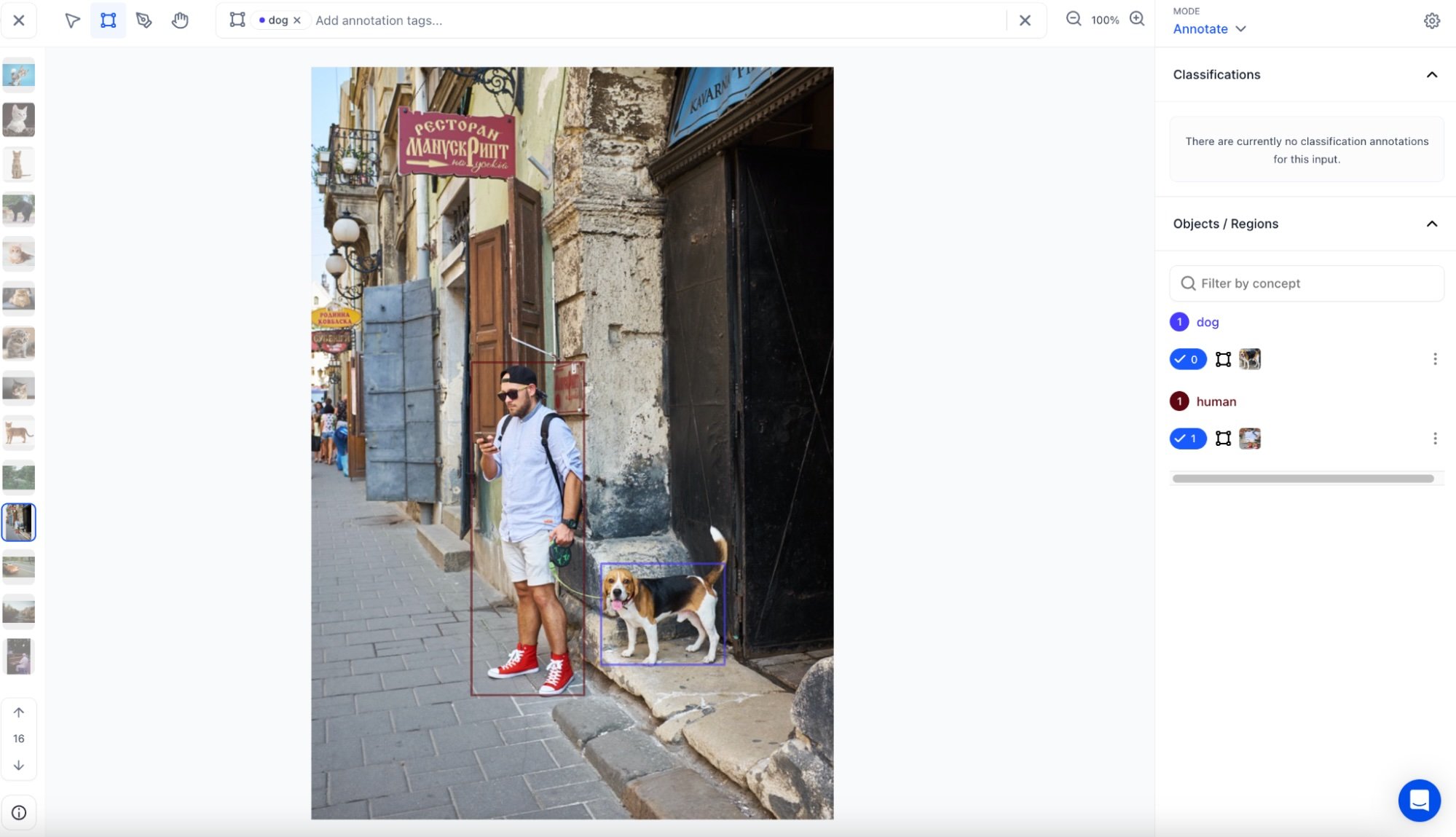
As you may be aware, the Clarifai platform enables you to annotate your data in various ways, including bounding boxes, segmentations, or simple labels. After annotating your dataset within the Clarifai App, we offer the capability to extract all annotations from the app in either JSON or dataframe format. From there, you have the flexibility to store it as you prefer, such as converting it into a delta table or saving it as a CSV file.
To obtain annotations within your Clarifai App's dataset, you can utilize the following function, which provides a JSON response. Additionally, you have the option to specify a list of input IDs for which you require annotations.
You can also acquire annotations in a structured dataframe format, including columns like annotation_id’, 'annotation', 'annotation_user_id', 'iinput_id', 'annotation_created_at' and ‘annotation_modified_at’. If necessary, you can specify a list of input IDs for which you require annotations. Please note that the JSON response may contain supplementary attributes.
You have the capability to retrieve both input details and their corresponding annotations simultaneously using the following function. This function produces a dataframe that consolidates data from both the annotations and inputs dataframes, as described in the functions mentioned earlier.
Let's go through an example where you fetch the annotations from your Clarifai App’s dataset and store them into a delta live table on Databricks.
In this blog we walked through the integration between Databricks and Clarifai using the ClarifaiPyspark SDK. The SDK covers a range of methods for ingesting and retrieving datasets, providing you with the ability to opt for the most suitable approach for your specific requirements. Whether you are uploading data from Databricks volumes or AWS S3 buckets, exporting data and annotations to preferred formats, or utilizing custom data loaders, the SDK offers a robust array of functionalities. Here’s our SDK GitHub repository - link.
More features and enhancements will be released in the near future to ensure a deepening integration between Databricks and Clarifai. Stay tuned for more updates and enhancements and send us any feedback to product-feedback@clarifai.com.




