-png.png?width=2880&height=1440&name=ML%20Lifecycle%20management%20(1)-png.png) ML Lifecycle Management Guide – Mastering the End‑to‑End Journey of Machine Learning
ML Lifecycle Management Guide – Mastering the End‑to‑End Journey of Machine Learning
Machine‑learning models are living organisms—they grow, adapt, and eventually degrade. Managing their lifecycle is the difference between a proof‑of‑concept and a sustainable AI product. This guide shows you how to plan, build, deploy, monitor, and govern models while tapping into Clarifai’s platform for orchestration, local execution, and generative AI.
Quick Digest—What Does This Guide Cover?
- Definition & Importance: Understand what ML lifecycle management means and why it matters.
- Planning & Data: Learn how to define business problems and collect and prepare data.
- Development & Deployment: See how to train, evaluate and deploy models.
- Monitoring & Governance: Discover strategies for monitoring, drift detection and compliance.
- Advanced Topics: Dive into LLMOps, edge deployments and emerging trends.
- Real‑World Stories: Explore case studies highlighting successes and lessons.
What Is ML Lifecycle Management?
Quick Summary: What does the ML lifecycle entail?
- ML lifecycle management covers the complete journey of a model, from problem framing and data engineering to deployment, monitoring and decommissioning. It treats data, models and code as co‑evolving artifacts and ensures they remain reliable, compliant and valuable over time.
Understanding the Full Lifecycle
Every machine‑learning (ML) project travels through several phases that often overlap and iterate. The lifecycle begins with clearly defining the problem, transitions into collecting and preparing data, moves on to model selection and training, and culminates in deploying models into production environments. However, the journey doesn’t end there—continuous monitoring, retraining and governance are critical to ensuring the model continues to deliver value.
A well‑managed lifecycle provides many benefits:
- Predictable performance: Structured processes reduce ad‑hoc experiments and inconsistent results.
- Reduced technical debt: Documentation and version control prevent models from becoming black boxes.
- Regulatory compliance: Governance mechanisms ensure that the model’s decisions are explainable and auditable.
- Operational efficiency: Automation and orchestration cut down deployment cycles and maintenance costs.
Expert Insights
- Holistic view: Experts emphasize that lifecycle management integrates data pipelines, model engineering and software integration, treating them as inseparable pieces of a product.
- Agile iterations: Leaders recommend iterative cycles – small experiments, quick feedback and regular adjustments.
- Compliance by design: Compliance isn’t an afterthought; incorporate ethical and legal considerations from the planning stage.
How Do You Plan and Define Your ML Project?
Quick Summary: Why is planning critical for ML success?
- Effective ML projects start with a clear problem definition, detailed objectives and agreed‑upon success metrics. Without alignment on business goals, models may solve the wrong problem or produce outputs that aren’t actionable.
Laying a Strong Foundation
Before you touch code or data, ask why the model is needed. Collaboration with stakeholders is vital here:
- Identify stakeholders and their objectives. Understand who will use the model and how its outputs will influence decisions.
- Define success criteria. Set measurable key performance indicators (KPIs) such as accuracy, recall, ROI or customer satisfaction.
- Outline constraints and risks. Consider ethical boundaries, regulatory requirements and resource limitations.
- Translate business goals into ML tasks. Frame the problem in ML terms (classification, regression, recommendation) while documenting assumptions.
Creative Example – Predictive Maintenance in Manufacturing
Imagine a factory wants to reduce downtime by predicting machine failures. Stakeholders (plant managers, maintenance teams, data scientists) meet to define the goal: prevent unexpected breakdowns. They agree on success metrics like “reduce downtime by 30 %” and set constraints such as “no additional sensors”. This clear planning ensures the subsequent data collection and modeling efforts are aligned.
Expert Insights
- Stakeholder interviews: Involve not just executives but also frontline operators; they often offer valuable context.
- Document assumptions: Record what you think is true about the problem (e.g., data availability, label quality) so you can revisit later.
- Alignment prevents scope creep: A defined scope keeps the team focused and prevents unnecessary features.
How to Engineer and Prepare Data for ML?
Quick Summary: What are the core steps in data engineering?
- Data engineering includes ingestion, exploration, validation, cleaning, labeling and splitting. These steps ensure that raw data becomes a reliable, structured dataset ready for modeling.
Data Ingestion & Integration
The first task is collecting data from diverse sources – databases, APIs, logs, sensors or third‑party feeds. Use frameworks like Spark or HDFS for large datasets, and document where each piece of data comes from. Consider generating synthetic data if certain classes are rare.
Exploration & Validation
Once data is ingested, profile it to understand distributions and detect anomalies. Compute statistics like mean, variance and cardinality; build histograms and correlation matrices. Validate data with rules: check for missing values, out‑of‑range numbers or duplicate entries.
Data Cleaning & Wrangling
Cleaning data involves fixing errors, imputing missing values and standardizing formats. Techniques range from simple (mean imputation) to advanced (time‑aware imputation for sequences). Standardize categorical values (e.g., unify “USA,” “United States,” “U.S.”) to avoid fragmentation.
Labeling & Splitting
Label each data point with the correct outcome, a task often requiring human expertise. Use annotation tools or Clarifai’s AI Lake to streamline labeling. After labeling, split the dataset into training, validation and test sets. Use stratified sampling to preserve class distributions.
Expert Insights
- Data quality > Model complexity: A simple algorithm on clean data often outperforms a complex algorithm on messy data.
- Iterative approach: Data engineering is rarely one‑and‑done. Plan for multiple passes as you discover new issues.
- Documentation matters: Track every transformation – regulators may require lineage logs for auditing.

How to Perform EDA and Feature Engineering?
Quick Summary: Why do you need EDA and feature engineering?
- Exploratory data analysis (EDA) uncovers patterns and anomalies that guide model design, while feature engineering transforms raw data into meaningful inputs.
Exploratory Data Analysis (EDA)
Start by visualizing distributions using histograms, scatter plots and box plots. Look for skewness, outliers and relationships between variables. Uncover patterns like seasonality or clusters; identify potential data leakage or mislabeled records. Generate hypotheses: for example, “Does weather affect customer demand?”
Feature Engineering & Selection
Feature engineering is the art of creating new variables that capture underlying signals. Common techniques include:
- Combining variables (e.g., ratio of clicks to impressions).
- Transforming variables (log, square root, exponential).
- Encoding categorical values (one‑hot encoding, target encoding).
- Aggregating over time (rolling averages, time since last purchase).
After generating features, select the most informative ones using statistical tests, tree‑based feature importance or L1 regularization.
Creative Example – Feature Engineering in Finance
Consider a credit‑scoring model. Beyond income and credit history, engineers create a “credit utilization ratio”, capturing the percentage of credit in use relative to the limit. They also compute “time since last delinquent payment” and “number of inquiries in the past six months.” These engineered features often have stronger predictive power than raw variables.
Expert Insights
- Domain expertise pays dividends: Collaborate with subject‑matter experts to craft features that capture domain nuances.
- Less is more: A smaller set of high‑quality features often outperforms a large but noisy set.
- Beware of leakage: Don’t use future information (e.g., last payment outcome) when training your model.
How to Develop, Experiment and Train ML Models?
Quick Summary: What are the key steps in model development?
- Model development involves selecting algorithms, training them iteratively, evaluating performance and tuning hyperparameters. Packaging models into portable formats (e.g., ONNX) facilitates deployment.
Selecting Algorithms
Choose models that fit your data type and problem:
- Structured data: Logistic regression, decision trees, gradient boosting.
- Sequential data: Recurrent neural networks, transformers.
- Images and video: Convolutional neural networks (CNNs).
Start with simple models to establish baselines, then progress to more complex architectures if needed.
Training & Hyperparameter Tuning
Training involves feeding labeled data into your model, optimizing a loss function via algorithms like gradient descent. Use cross‑validation to avoid overfitting and evaluate different hyperparameter settings. Tools like Optuna or hyperopt automate search across hyperparameters.
Evaluation & Tuning
Evaluate models using appropriate metrics:
- Classification: Accuracy, precision, recall, F1 score, AUC.
- Regression: Mean Absolute Error (MAE), Root Mean Squared Error (RMSE).
Tune hyperparameters iteratively – adjust learning rates, regularization parameters or architecture depth until performance plateaus.
Packaging for Deployment
Once trained, export your model to a standardized format like ONNX or PMML. Version the model and its metadata (training data, hyperparameters) to ensure reproducibility.
Expert Insights
- No free lunch: Complex models can overfit; always benchmark against simpler baselines.
- Fairness & bias: Evaluate your model across demographic groups and implement mitigation if needed.
- Experiment tracking: Use tools like Clarifai’s built‑in tracking or MLflow to log hyperparameters, metrics and artifacts.
How to Deploy and Serve Your Model?
Quick Summary: What are the best practices for deployment?
- Deployment transforms a trained model into an operational service. Choose the right serving pattern (batch, real‑time or streaming) and leverage containerization and orchestration tools to ensure scalability and reliability.
Deployment Strategies
- Batch inference: Suitable for offline analytics; run predictions on a schedule and write results to storage.
- Real‑time inference: Deploy models as microservices accessible via REST/gRPC APIs to provide immediate predictions.
- Streaming inference: Process continuous data streams (e.g., Kafka topics) and update models frequently.
Infrastructure & Orchestration
Package your model in a container (Docker) and deploy it on a platform like Kubernetes. Implement autoscaling to handle varying loads and ensure resilience. For serverless deployments, consider cold‑start latency.
Testing & Rollbacks
Before going live, perform integration tests to ensure the model works within the larger application. Use blue/green deployment or canary release strategies to roll out updates incrementally and roll back if issues arise.
Expert Insights
- Model performance monitoring: Even after deployment, performance may vary due to changing data; see the monitoring section next.
- Infrastructure as code: Use Terraform or CloudFormation to define your deployment environment, ensuring consistency across stages.
- Clarifai’s edge: Deploy models using Clarifai’s compute orchestration platform to manage resources across cloud, on‑prem and edge.
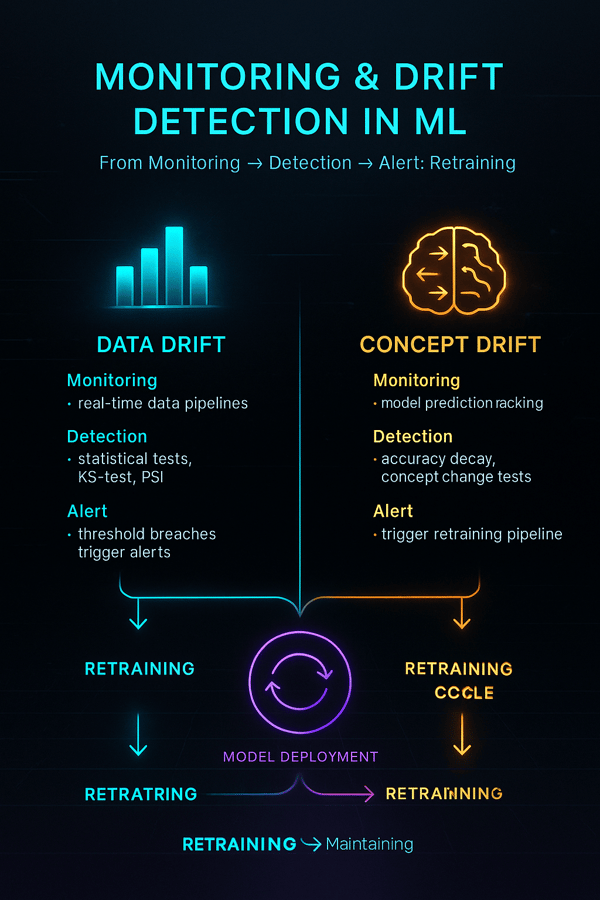
How to Monitor Models and Manage Drift?
Quick Summary: Why is monitoring essential?
- Models degrade over time due to data drift, concept drift and changes in the environment. Continuous monitoring tracks performance, detects drift and triggers retraining.
Monitoring Metrics
- Functional performance: Track metrics like accuracy, precision, recall or MAE on real‑world data.
- Operational performance: Monitor latency, throughput and resource utilization.
- Drift detection: Measure differences between training data distribution and incoming data. Tools like Evidently AI and NannyML excel at detecting general drift and pinpointing drift timing respectively.
Alerting & Retraining
Set thresholds for metrics; trigger alerts and remedial actions when thresholds are breached. Automate retraining pipelines so the model adapts to new data patterns.
Creative Example – E‑commerce Demand Forecasting
A retailer’s demand‑forecasting model suffers a drop in accuracy after a major marketing campaign. Monitoring picks up the data drift and triggers retraining with post‑campaign data. This timely retraining prevents stockouts and overstock issues, saving millions.
Expert Insights
- Amazon’s lesson: During the COVID‑19 pandemic, Amazon’s supply‑chain models failed due to unexpected demand spikes – a cautionary tale on the importance of drift detection.
- Comprehensive monitoring: Track both input distributions and prediction outputs for a complete picture.
- Clarifai’s dashboard: Clarifai’s Model Performance Dashboard visualizes drift, performance degradation and fairness metrics.
Why Do Model Governance and Risk Management Matter?
Quick Summary: What is model governance?
- Model governance ensures that models are transparent, accountable and compliant. It encompasses processes that control access, document lineage and align models with legal requirements.
Governance & Compliance
Model governance integrates with MLOps by covering six phases: business understanding, data engineering, model engineering, quality assurance, deployment and monitoring. It enforces access control, documentation and auditing to meet regulatory requirements.
Regulatory Frameworks
- EU AI Act: Classifies AI systems into risk categories. High‑risk systems must satisfy strict documentation, transparency and human oversight requirements.
- NIST AI RMF: Suggests functions (Govern, Map, Measure, Manage) that organizations should perform throughout the AI lifecycle.
- ISO/IEC 42001: An emerging standard that will specify AI management system requirements.
Implementing Governance
Establish roles and responsibilities, separate model builders from validators, and create an AI board involving legal, technical and ethics experts. Document training data sources, feature selection, model assumptions and evaluation results.
Expert Insights
- Comprehensive records: Keeping detailed records of model decisions and interactions helps in investigations and audits.
- Ethical AI: Governance is not just about compliance – it ensures that AI systems align with organizational values and social expectations.
- Clarifai’s tools: Clarifai’s Control Center offers granular permission controls and SOC2/ISO 27001 compliance out of the box, easing governance burdens.

How to Ensure Reproducibility and Track Experiments?
Quick Summary: Why is reproducibility important?
- Reproducibility ensures that models can be consistently rebuilt and audited. Experiment tracking centralizes metrics and artifacts for comparison and collaboration.
Version Control & Data Lineage
Use Git for code and DVC (Data Version Control) or Git‑LFS for large datasets. Log random seeds, environment variables and library versions to avoid non‑deterministic results. Keep transformation scripts under version control.
Experiment Tracking
Tools like MLflow, Neptune.ai or Clarifai’s built‑in tracker enable you to log hyperparameters, metrics, artifacts and environment details, and tag experiments for easy retrieval. Use dashboards to compare runs and decide which models to promote.
Model Registry
A model registry is a centralized store for models and their metadata. It tracks versions, performance, stage (staging, production), and references to data and code. Unlike object storage, a registry provides context and supports rollbacks.
Expert Insights
- Reproducibility is non‑negotiable for regulated industries; auditors may request to reproduce a prediction made years ago.
- Tags and naming conventions: Use consistent naming patterns for experiments to avoid confusion.
- Clarifai’s advantage: Clarifai’s platform integrates experiment tracking and model registry, so models move seamlessly from development to deployment.
How to Automate Your ML Lifecycle?
Quick Summary: What role does automation play in MLOps?
- Automation streamlines repetitive tasks, accelerates releases and reduces human error. CI/CD pipelines, continuous training and infrastructure‑as‑code are key mechanisms.
CI/CD for Machine Learning
Adopt continuous integration and delivery pipelines:
- Continuous integration: Automate code tests, data validation and static analysis on every commit.
- Continuous delivery: Automate deployment of models to staging environments.
- Continuous training: Trigger training jobs automatically when new data arrives or drift is detected.
Infrastructure‑as‑Code & Orchestration
Define infrastructure (compute, networking, storage) using Terraform or CloudFormation to ensure consistent and repeatable environments. Use Kubernetes to orchestrate containers and implement autoscaling.
Clarifai Integration
Clarifai’s compute orchestration simplifies automation: you can deploy your models anywhere (cloud, on‑prem or edge) and scale them automatically. Local runners let you test or run models offline using the same API, making CI/CD pipelines more robust.
Expert Insights
- Automate tests: ML pipelines need tests beyond unit tests – include checks for data schema and distribution.
- Small increments: Deploying small changes more frequently reduces risk.
- Self‑healing pipelines: Build pipelines that react to drift detection by automatically retraining and redeploying.
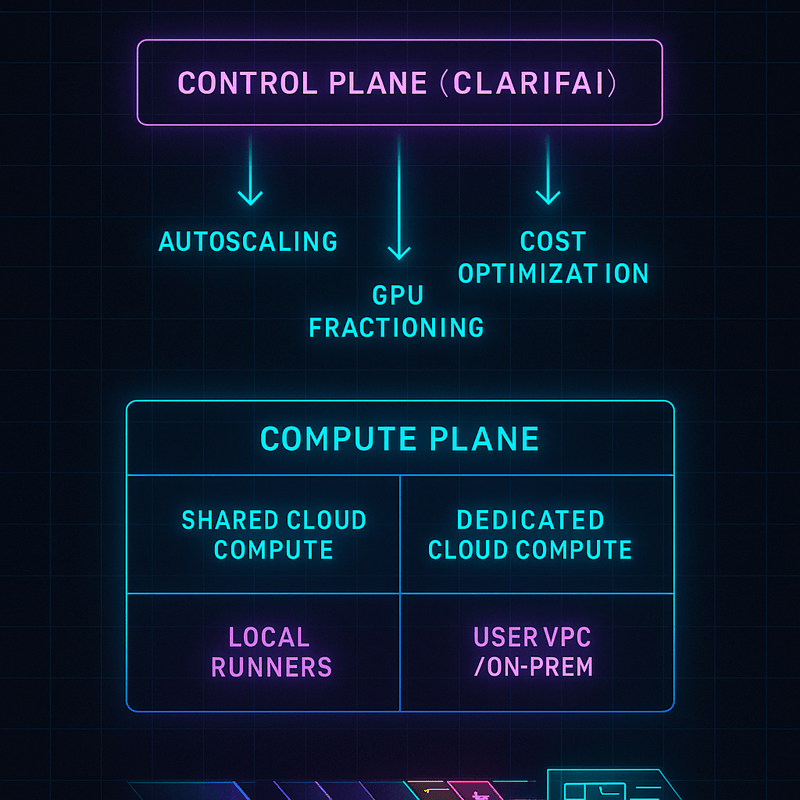
How to Orchestrate Compute Resources Effectively?
Quick Summary: What is compute orchestration and why is it important?
- Compute orchestration manages the allocation and scaling of hardware resources (CPU, GPU, memory) across different environments (cloud, on‑prem, edge). It optimizes cost, performance and reliability.
Hybrid Deployment Options
Organizations can choose from:
- Shared cloud: Pay‑as‑you‑go compute resources managed by providers.
- Dedicated cloud: Dedicated environments for predictable performance.
- On‑premise: For data sovereignty or latency requirements.
- Edge: For real‑time inference near data sources.
Clarifai’s Hybrid Platform
Clarifai’s platform offers a unified control plane where you can orchestrate workloads across shared compute, dedicated environments and your own VPC or edge hardware. Autoscaling and cost optimization features help right‑size compute and allocate resources dynamically.
Cost Optimization Strategies
- Right‑size instances: Choose instance types matching workload demands.
- Spot instances: Reduce costs by using spare capacity at discounted rates.
- Scheduling: Run compute‑intensive tasks during off‑peak hours to save on electricity and cloud fees.
Expert Insights
- Resource monitoring: Continuously monitor resource utilization to avoid idle capacity.
- MIG (Multi‑Instance GPU): Partition GPUs to run multiple models concurrently, improving utilization.
- Clarifai’s local runners keep compute local to reduce latency and cloud costs.
How to Deploy Models at the Edge and On‑Device?
Quick Summary: What are edge deployments and when are they useful?
- Edge deployments run models on devices close to where data is generated, reducing latency and preserving privacy. They’re ideal for IoT, mobile and remote environments.
Why Edge?
Edge inference avoids round‑trip latency to the cloud and ensures models continue to operate even if connectivity is intermittent. It also keeps sensitive data local, which may be crucial for regulated industries.
Tools and Frameworks
- TensorFlow Lite, ONNX Runtime and Core ML enable models to run on mobile phones and embedded devices.
- Hardware acceleration: Devices like NVIDIA Jetson or smartphone NPUs provide the processing power needed for inference.
- Resilient updates: Use over‑the‑air updates with rollback to ensure reliability.
Clarifai’s Edge Solutions
Clarifai’s local runners deliver consistent APIs across cloud and edge and can run on devices like Jetson. They allow you to test locally and deploy seamlessly with minimal code changes.
Expert Insights
- Model size matters: Compress models via quantization or pruning to fit on resource‑constrained devices.
- Data capture: Collect telemetry from edge devices to improve models over time.
- Connectivity planning: Implement caching and asynchronous syncing to handle network outages.
What Is LLMOps and How to Handle Generative AI?
Quick Summary: How is LLMOps different from MLOps?
- LLMOps applies lifecycle management to large language models (LLMs) and generative AI, addressing unique challenges like prompt management, privacy and hallucination detection.
The Rise of Generative AI
Large language models (LLMs) like GPT‑family and Claude can generate text, code and even images. Managing these models requires specialized practices:
- Model selection: Evaluate open models and choose one that fits your domain.
- Customisation: Fine‑tune or prompt‑engineer the model for your specific task.
- Data privacy: Use pseudonymisation or anonymisation to protect sensitive data.
- Retrieval‑Augmented Generation (RAG): Combine LLMs with vector databases to fetch accurate facts while keeping proprietary data off the model’s training corpus.
Prompt Management & Evaluation
- Prompt repositories: Store and version prompts just like code.
- Guardrails: Monitor outputs for hallucinations, toxicity or bias. Use tools like Clarifai’s generative AI evaluation service to measure and mitigate issues.
Clarifai’s Generative AI Offering
Clarifai provides pre‑trained text and image generation models with APIs for easy integration. Their platform allows you to fine‑tune prompts and evaluate generative output with built‑in guardrails.
Expert Insights
- LLMs can be unpredictable: Always test prompts across diverse inputs.
- Ethical considerations: LLMs can produce harmful or biased content; implement filters and oversight mechanisms.
- LLM cost: Generative models require substantial compute. Using Clarifai’s hybrid compute orchestration helps you manage costs while leveraging the latest models.
Why Is Collaboration Essential for MLOps?
Quick Summary: How do teams collaborate in MLOps?
- MLOps is inherently cross‑functional, requiring cooperation between data scientists, ML engineers, operations teams, product owners and domain experts. Effective collaboration hinges on communication, shared tools and mutual understanding.
Building Cross‑Functional Teams
- Roles & Responsibilities: Define roles clearly (data engineer, ML engineer, MLOps engineer, domain expert).
- Shared Documentation: Maintain documentation of datasets, feature definitions and model assumptions in collaborative platforms (Confluence, Notion).
- Communication Rituals: Conduct daily stand‑ups, weekly syncs and retrospectives to align objectives.
Early Involvement of Domain Experts
Domain experts should be part of planning, feature engineering and evaluation phases to catch mistakes and add context. Encourage them to review model outputs and highlight anomalies.
Expert Insights
- Psychological safety: Foster an environment where team members can question assumptions without fear.
- Training: Encourage cross‑training – engineers learn domain context; domain experts gain ML literacy.
- Clarifai’s Community: Clarifai offers community forums and support channels to help teams collaborate and get expert help.
What Do Real‑World Case Studies Teach Us?
Quick Summary: What lessons come from real deployments?
- Real‑world case studies reveal the importance of monitoring, edge deployment and preparedness for drift. They highlight how Clarifai’s platform accelerates success.
Ride‑Sharing – Handling Weather‑Driven Drift
A ride‑sharing company monitored travel‑time predictions using Clarifai’s dashboard. When heavy rain caused unusual travel patterns, drift detection flagged the change. An automated retraining job updated the model with the new data, preventing inaccurate ETAs and maintaining user trust.
Manufacturing – Edge Monitoring of Machines
A factory deployed a computer‑vision model to detect equipment anomalies. Using Clarifai’s local runner on Jetson devices, they achieved real‑time inference without sending video to the cloud. Night‑time updates ensured the model stayed current without disrupting production.
Supply Chain – Consequences of Ignoring Drift
During COVID‑19, Amazon’s supply‑chain prediction algorithms failed due to unprecedented demand spikes for household goods, leading to bottlenecks. The lesson: incorporate extreme scenarios into risk management and monitor for unexpected drifts.
Benchmarking Drift Detection Tools
Researchers evaluated open‑source drift tools and found Evidently AI best for general drift detection and NannyML for pinpointing drift timing. Choosing the right tool depends on your use case.
Expert Insights
- Monitoring pays off: Early detection and retraining saved the ride‑sharing and manufacturing companies from costly errors.
- Edge vs cloud: Edge deployments cut latency but require strong update mechanisms.
- Tool selection: Evaluate tools for functionality, scalability, and integration ease.
What Future Trends Will Shape ML Lifecycle Management?
Quick Summary: Which trends should you watch?
- Responsible AI frameworks (NIST AI RMF, EU AI Act) and standards (ISO/IEC 42001) will shape governance, while LLMOps, federated learning, and AutoML will transform development.
Responsible AI & Regulation
The NIST AI RMF encourages organizations to govern, map, measure and manage AI risks. The EU AI Act categorizes systems by risk and will require high‑risk models to pass conformity assessments. ISO/IEC 42001 is in development to standardize AI management.
LLMOps & Generative AI
As generative models proliferate, LLMOps will become essential. Expect new tools for prompt management, fairness auditing and generative content identification.
Federated Learning & Privacy
Federated learning will enable collaborative training across multiple devices without sharing raw data, boosting privacy and complying with regulations. Differential privacy and secure aggregation will further protect sensitive information.
Low‑Code/AutoML & Citizen Data Scientists
AutoML platforms will democratize model development, enabling non‑experts to build models. However, organizations must balance automation with governance and oversight.
Research Gaps & Opportunities
A systematic mapping study highlights that few research papers tackle deployment, maintenance and quality assurance. This gap offers opportunities for innovation in MLOps tooling and methodology.
Expert Insights
- Stay adaptable: Regulations will evolve; build flexible governance and compliance processes.
- Invest in education: Equip your team with knowledge of ethics, law and emerging technologies.
- Clarifai’s roadmap: Clarifai continues to integrate emerging practices (e.g., RAG, generative AI guardrails) into its platform, making it easier to adopt future trends.
Conclusion – How to Get Started and Succeed
Managing the ML lifecycle is a marathon, not a sprint. By planning carefully, preparing data meticulously, experimenting responsibly, deploying robustly, monitoring continuously and governing ethically, you set the stage for long‑term success. Clarifai’s hybrid AI platform offers tools for orchestration, local execution, model registry, generative AI and fairness auditing, making it easier to adopt best practices and accelerate time to value.
Actionable Next Steps
- Audit your workflow: Identify gaps in version control, data quality or monitoring.
- Implement data pipelines: Automate ingestion, validation and cleaning.
- Track experiments: Use an experiment tracker and model registry.
- Automate CI/CD: Build pipelines that test, train and deploy models continuously.
- Monitor & retrain: Set up drift detection and automated retraining triggers.
- Prepare for compliance: Document data sources, features and evaluation metrics; adopt frameworks like NIST AI RMF.
- Explore Clarifai: Leverage Clarifai’s compute orchestration, local runners and generative AI tools to simplify infrastructure and accelerate innovation.
Frequently Asked Questions
Q1: How frequently should models be retrained?
Retraining frequency depends on data drift and business requirements. Use monitoring to detect when performance drops below acceptable thresholds and trigger retraining.
Q2: What differentiates MLOps from LLMOps?
MLOps manages any machine‑learning model’s lifecycle, while LLMOps focuses on large language models, adding challenges like prompt management, privacy preservation and hallucination detection.
Q3: Are edge deployments always better?
No. Edge deployments reduce latency and improve privacy, but they require lightweight models and robust update mechanisms. Use them when latency, bandwidth or privacy demands outweigh the complexity.
Q4: How do model registries improve reproducibility?
Model registries store versions, metadata and deployment status, making it easy to roll back or compare models; object storage alone lacks this context.
Q5: What does Clarifai offer beyond open‑source tools?
Clarifai provides end‑to‑end solutions, including compute orchestration, local runners, experiment tracking, generative AI tools and fairness audits, combined with enterprise‑grade security and support




