Cross-modal search is an emerging frontier in the world of information retrieval and data science. It represents a paradigm shift from traditional search methods, allowing users to query across diverse data types, such as text, images, audio, and video. It breaks down the barriers between different data modalities, offering a more holistic and intuitive search experience. This blog post aims to explore the concept of cross-modal search and its potential applications, and dive into the technical intricacies that make it possible. As the digital world continues to expand and diversify, cross-modal search technology is paving the way for more advanced, flexible, and accurate data retrieval.
Unimodal, cross-modal, and multimodal search are terms that refer to the types of data inputs or sources that an artificial intelligence system uses to perform search tasks. Here’s a brief explanation of each:
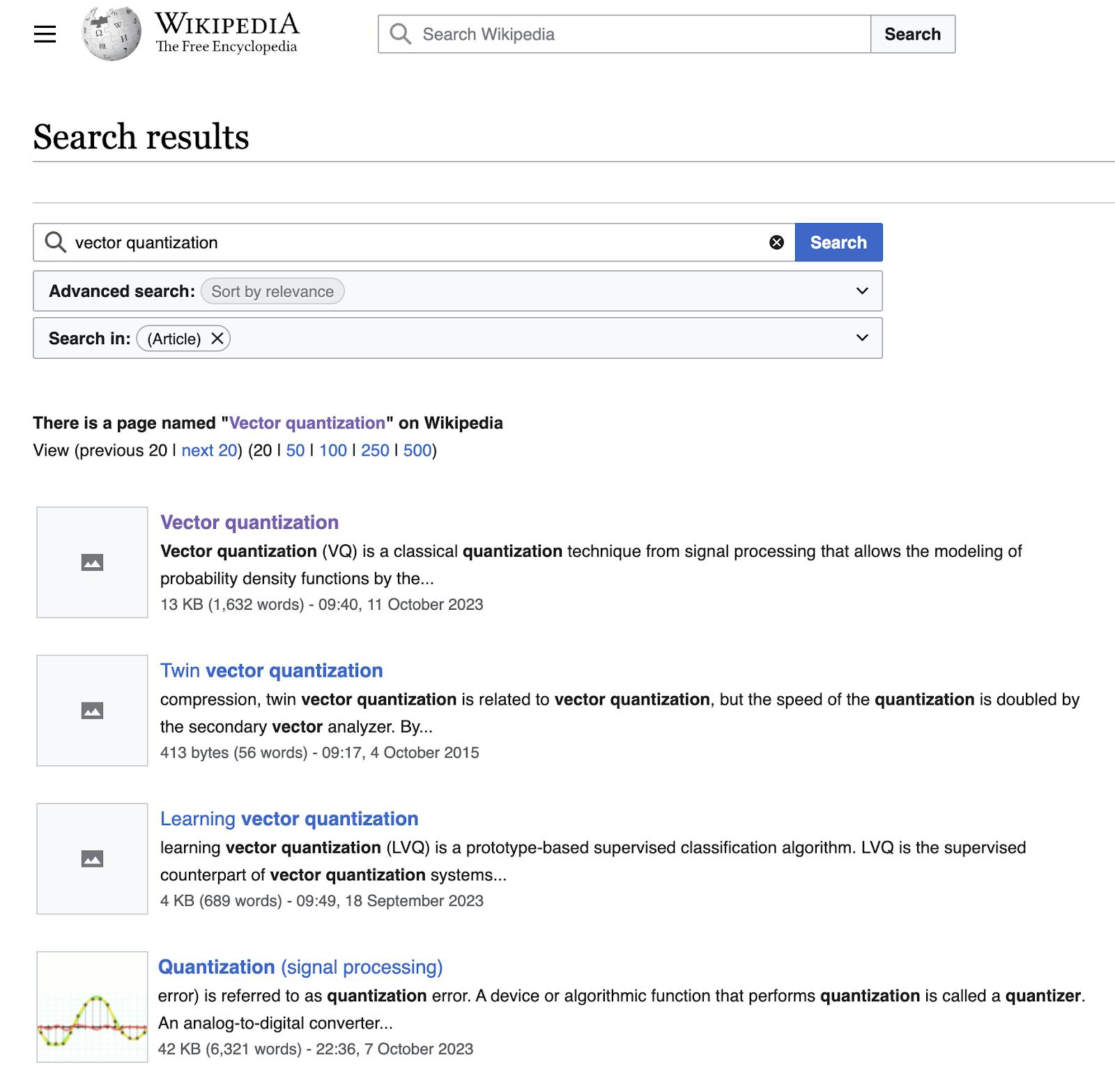
Example Wikipedia article search on “vector quantization”
With Clarifai, you could use the “General” workflow for image-to-image search and the “Text” workflow for text-to-text search, both unimodal. Previously, to mimic text-to-image (cross-modal) search, we’d leverage the 9000+ concepts in the General model as our vocabulary. Now with the advent of visual-language models like CLIP, we launched the “Universal” workflow to enable anyone to use natural language to search over images.
Operations can be done via the API or the portal UI. First, login to your account or sign up here for free.
In this example, we will use Clarifai’s Python SDK to help us use as few lines as possible. Before you get started, get your Personal Access Token (PAT) by following these steps. Also follow the homepage instructions to install the SDK in one step. Use this notebook to follow along in your development environment or in Google Colab.
1. Create a new app with the default workflow specified as the “Universal” workflow
2. Upload the following 3 example images. Since this is a short demo, we directly ingest the inputs into the app. For production purposes, we recommend using datasets to organize your inputs. The SDK currently supports uploading from a csv file and from a folder and you can find the details in the examples.
3. Perform search by calling the query method and passing in a ranking.
4. Response is a generator. See the results by checking the “hits” attribute.
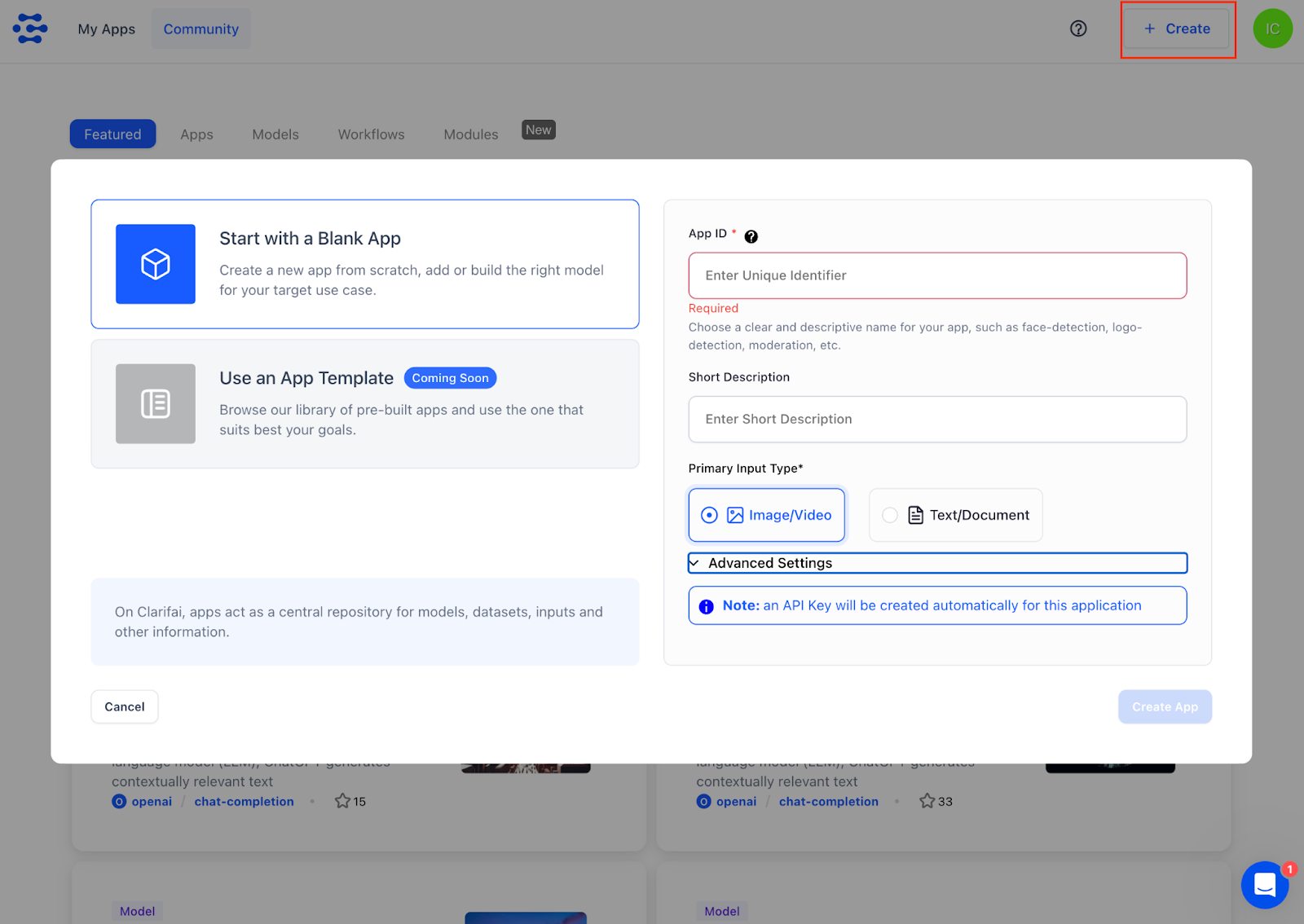
1. Create a new app by clicking the “+ Create” button on the top right corner in the portal screen. By default, “Start with a Blank App” is selected for you. For “Primary Input Type”, leave the default “Image/Video” selected as it sets the app’s base workflow with the Universal workflow. To verify that, click on “Advanced Settings”. Once the App ID and the short description have been filled in, click “Create App”.
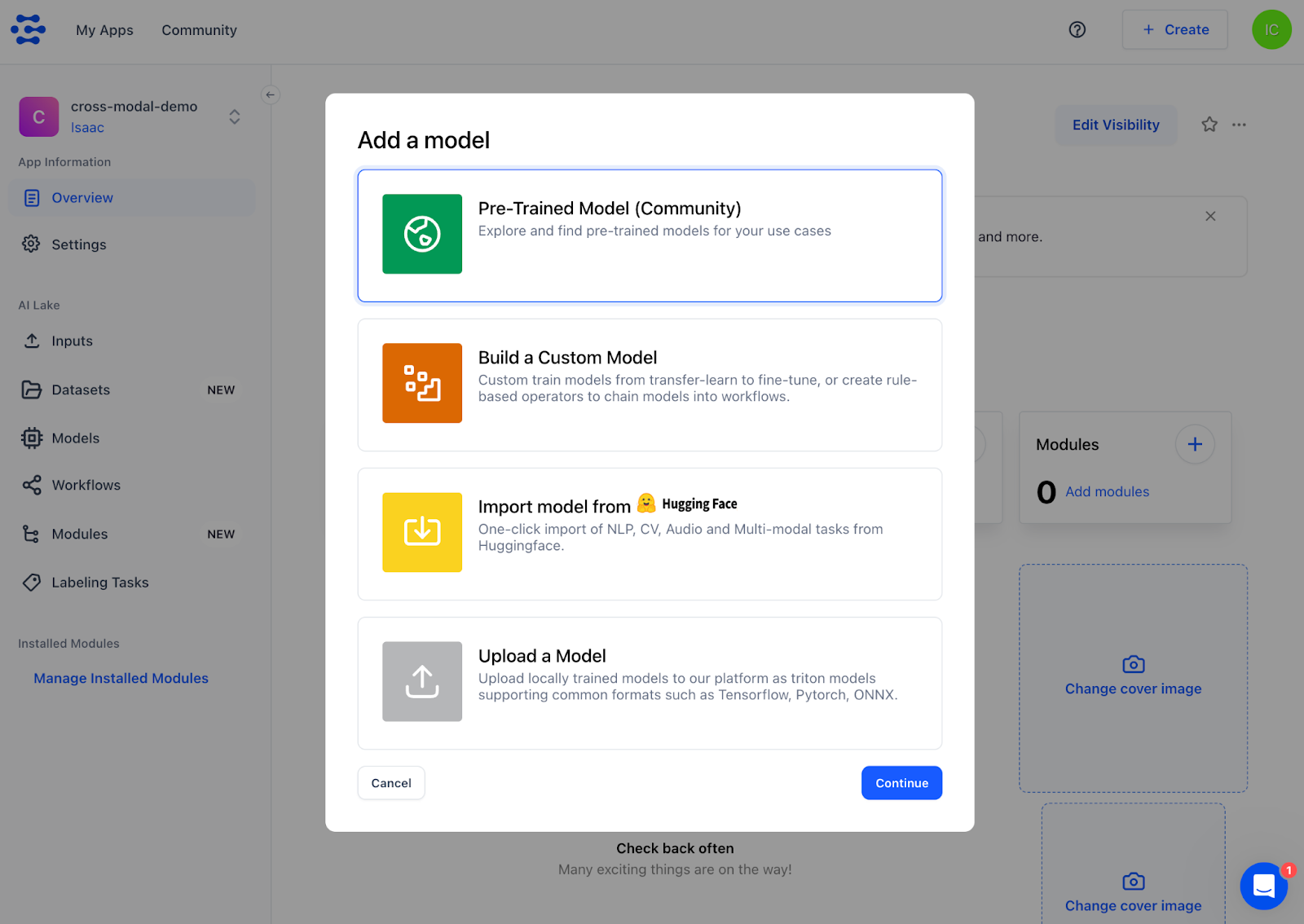
2. You’ll then be automatically navigated to the app you just created. At this time, you might see the following “Add a model” pop-up. Click “Cancel” on the bottom left corner as we do not need this for our tutorial.
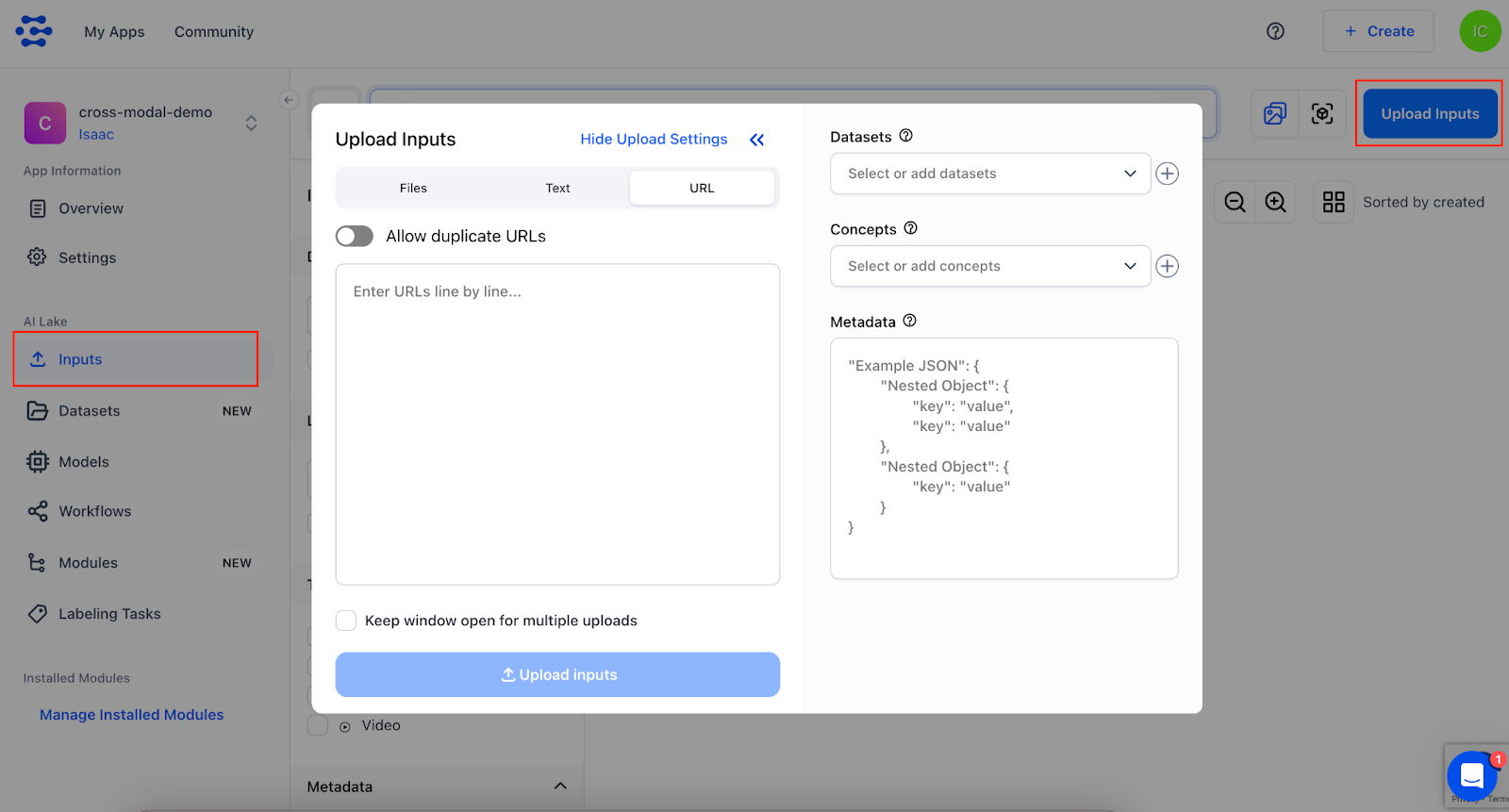
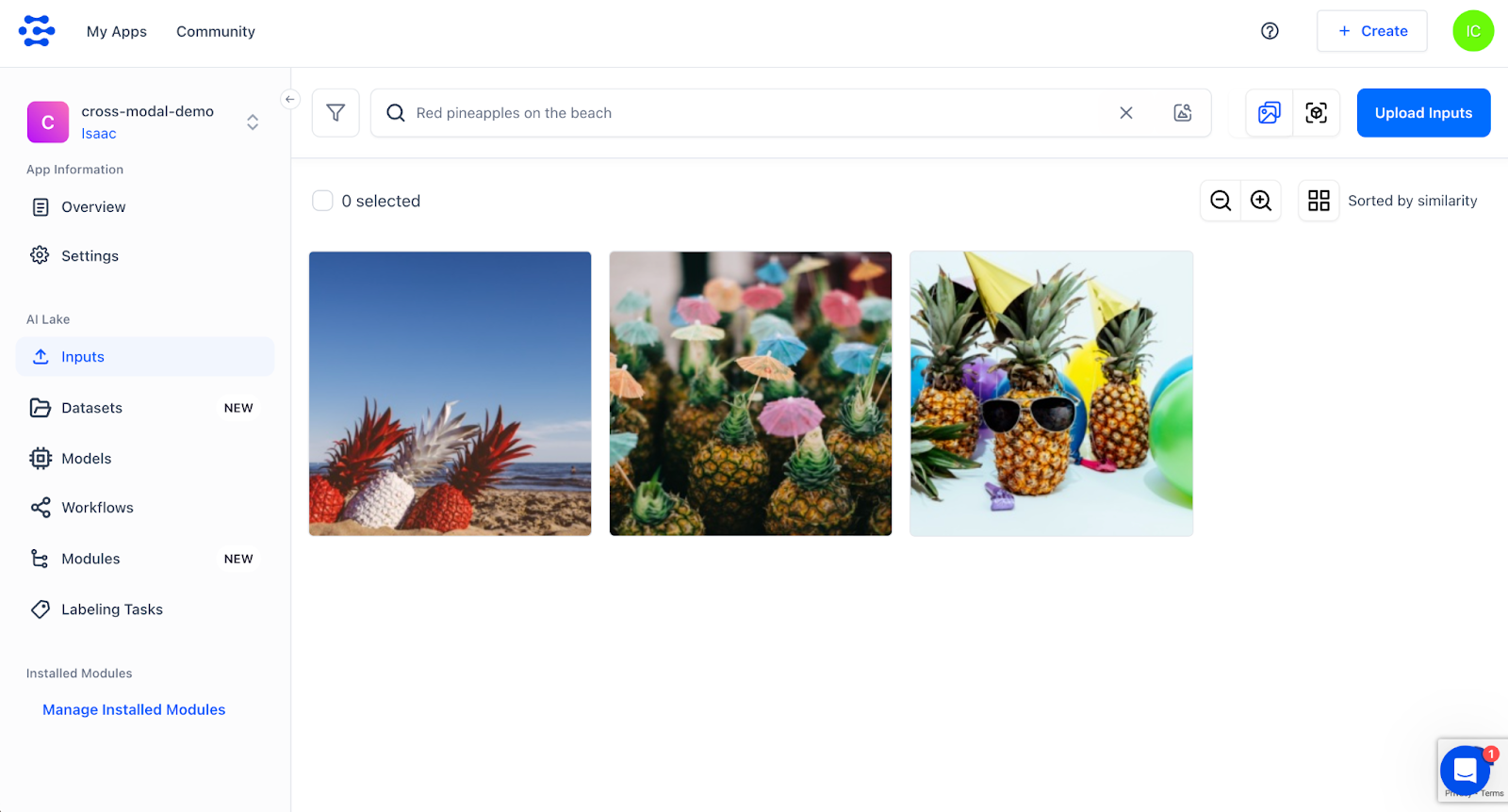
3. Upload images! On the left sidebar, click “Inputs”. Then click the blue button “Upload Inputs” on the top right. We can enter the image URLs line by line. Alternatively, we can upload them via a CSV file with a specific format. Here we use the following URLs. Copy and paste these into the box without new lines.
4. After the upload is complete, you should see all 3 images. In the search bar, enter a text query and hit enter. Here we have used “Red pineapples on the beach” as an example, and indeed, the search returns a ranked list with the most semantically similar image first.
The choice between unimodal, cross-modal, and multimodal search depends on the nature of your data and the goals of your search. If you need to find information across different types of data, a cross-modal search is necessary. As AI technology advances, there is a growing trend towards multimodal and cross-modal systems due to their ability to provide richer and more contextually relevant search results.
If you're looking to scale and deploy custom models, open-source models, or third-party models, Clarifai’s Compute Orchestration lets you deploy AI workloads on your dedicated cloud compute or within your own VPCs, on-premise, hybrid, or edge environments from a unified control plane. It offers flexibility without vendor lock-in, providing the capability to handle even the large multimodal models with ease. Check out Compute Orchestration.
Can’t find what you need? Checkout our Docs Page or send us a message in our Community Discord channel.