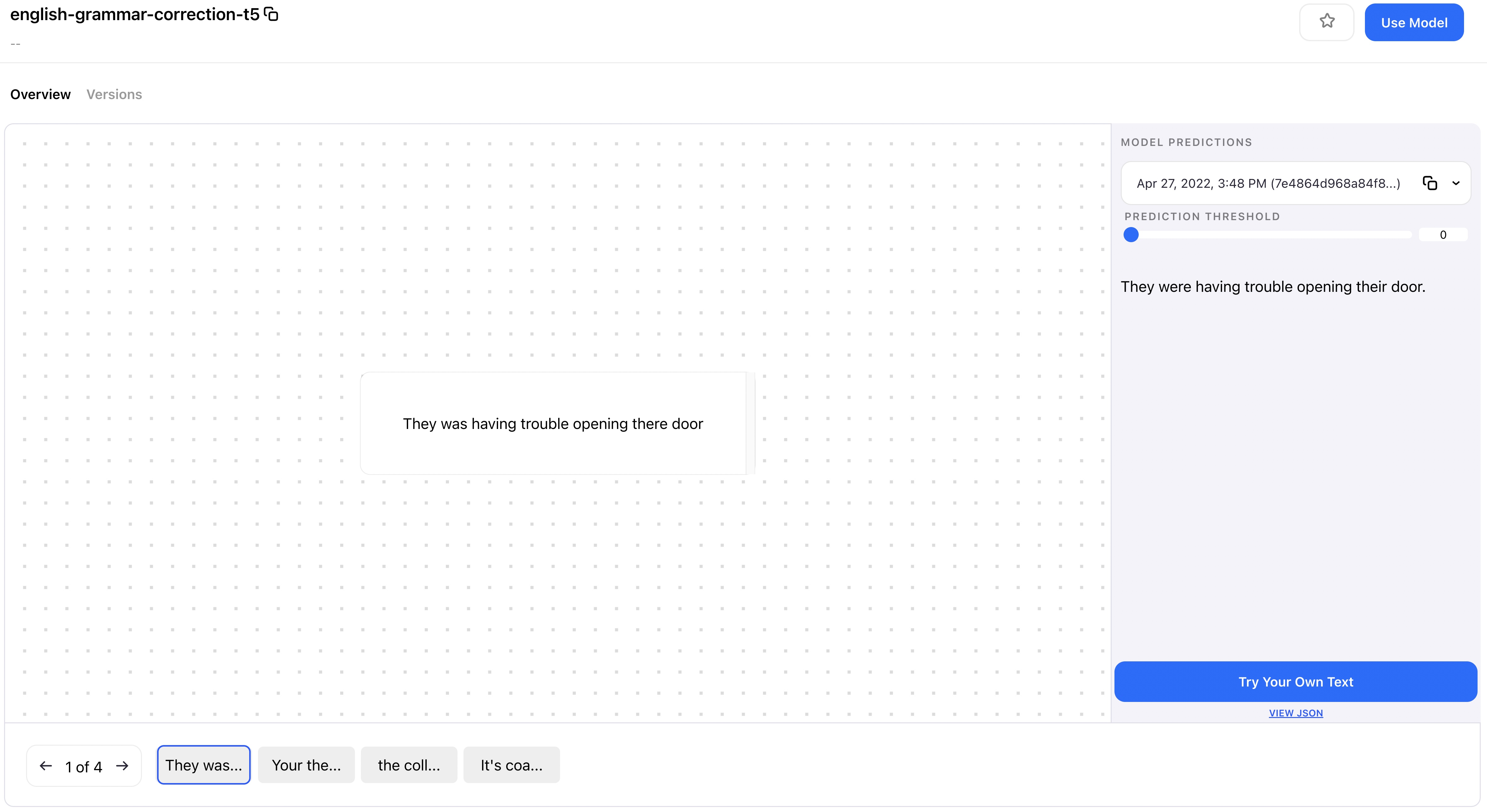
This month we've added new models for caption generation, printed OCR, grammar correction, and logo detection!
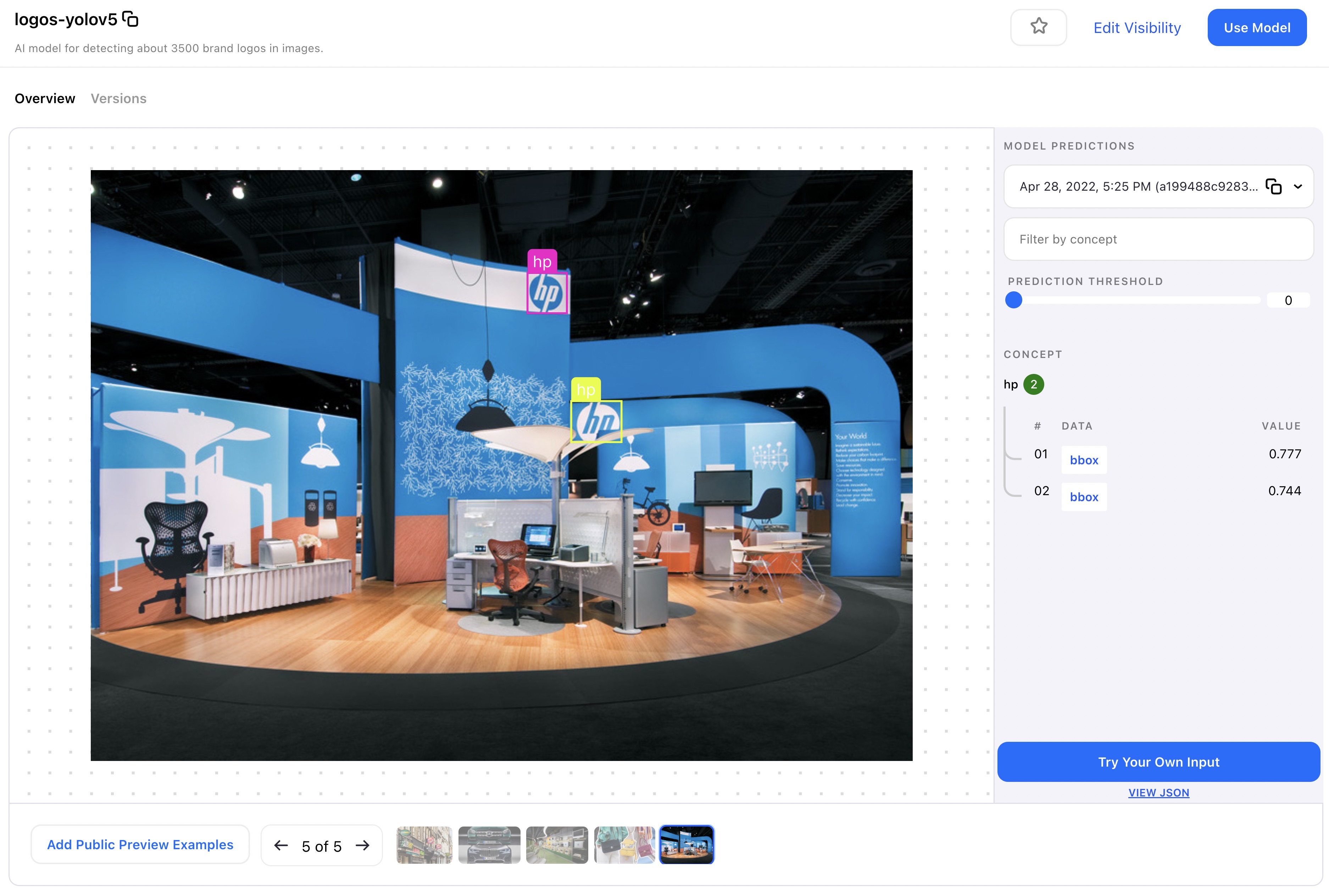
Find logos in images and video with this model! It was trained on the combination of LogoDet3k, OpenLogos, and Clarifai's internal logo dataset for a total of nearly 3,500 logos that can be detected.
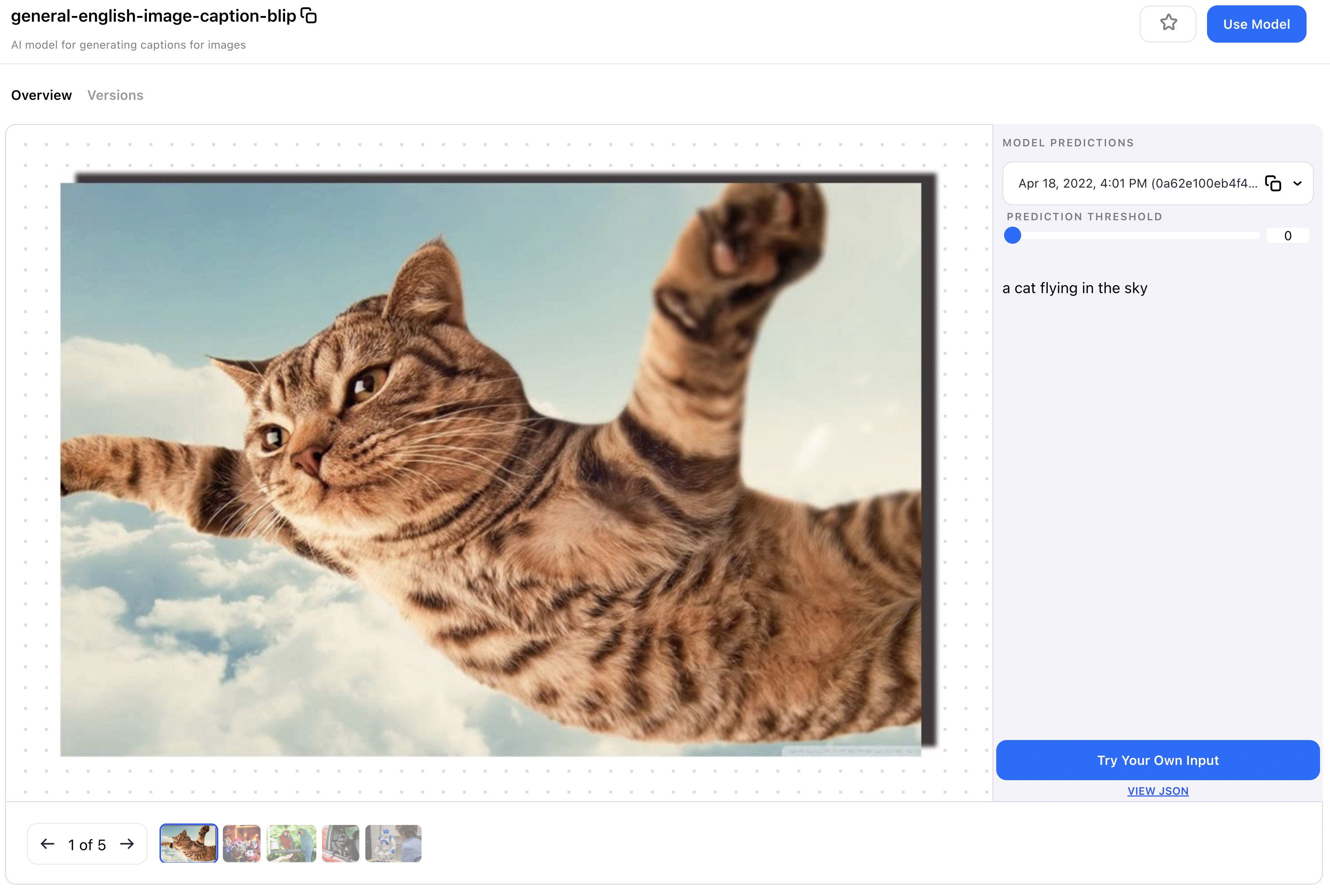
BLIP is a new pre-training framework for unified vision-language understanding and generation, which achieves state-of-the-art results on a wide range of vision-language tasks. This is a model from Salesforce that generates image captions; for a full deep dive check out their blog post or the research paper.
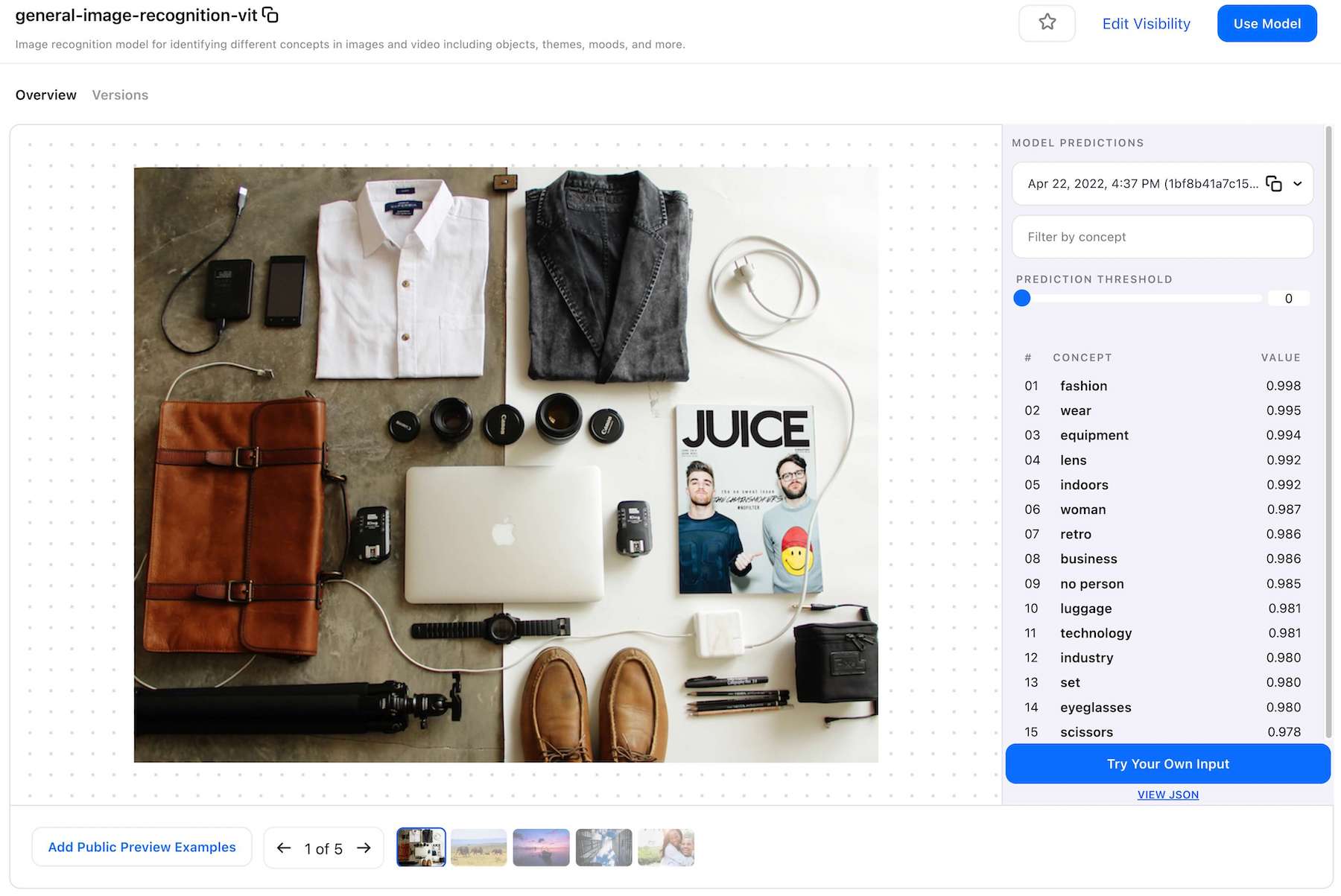
The vision transformer is a great all-purpose solution for most visual recognition needs with industry-leading performance.

Optical Character Recognition model based on Microsoft's Transformer OCR for recognizing printed texts. The TrOCR model was fine-tuned on the SROIE dataset. It was introduced in the paper TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models by Li et al. and first released in this repository.
The TrOCR model is an encoder-decoder model, consisting of an image Transformer as encoder, and a text Transformer as decoder. The image encoder was initialized from the weights of BEiT, while the text decoder was initialized from the weights of RoBERTa.
Images are presented to the model as a sequence of fixed-size patches (resolution 16x16), which are linearly embedded. One also adds absolute position embeddings before feeding the sequence to the layers of the Transformer encoder. Next, the Transformer text decoder autoregressively generates tokens.

Human and machine generated text often suffer from grammatical and/or typographical errors. It can be spelling, punctuation, grammatical or word choice errors. Gramformer is a library that exposes 3 separate interfaces to a family of algorithms to detect, highlight and correct grammar errors. To make sure the corrections and highlights recommended are of high quality, it comes with a quality estimator. You can use Gramformer in one or more areas mentioned under the "use-cases" section below or any other use case as you see fit. Gramformer stands on the shoulders of giants, it combines some of the top notch researches in grammar correction.