Clarifai Community
Published the HuggingFace text classification template
The HuggingFace text classification template is now available to users. You can use the pre-configured text classifier model template to train with your data and improve the accuracy of your results.
To use the template, when you create a model, choose Text Classifier > Template > Select "HuggingFace".
Text classification is a common NLP task that assigns a label or class to text. Some of the largest companies run text classification in production for a wide range of practical applications. One of the most popular forms of text classification is sentiment analysis, which assigns a label like 🙂 positive, 🙁 negative, or 😐 neutral to a sequence of text.
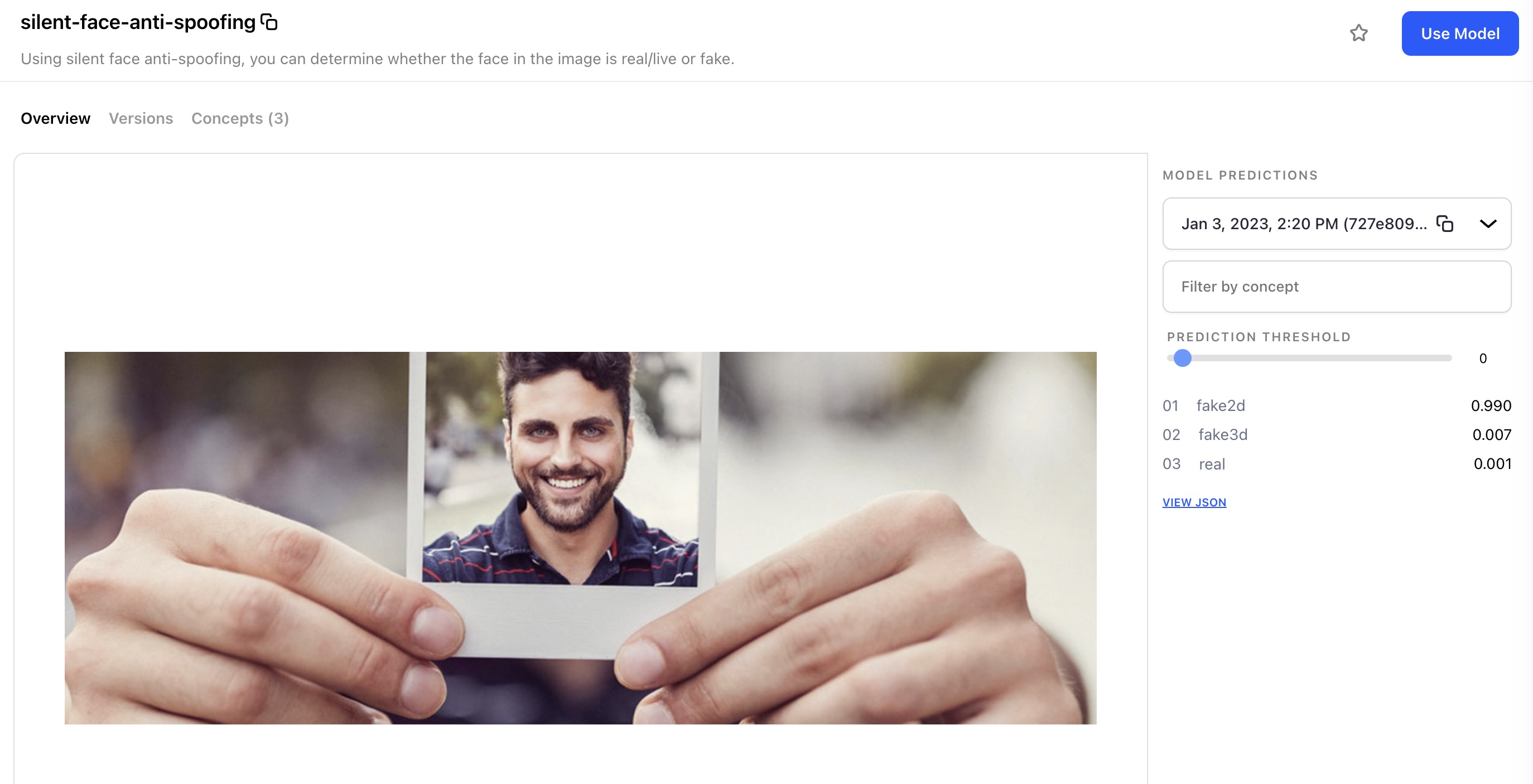
Published the silent-face-anti-spoofing model
The silent face anti-spoofing detection model is used to determine if the face in an image is a spoofing attempt or not.
It is designed to prevent people from tricking facial identification systems, such as those used for unlocking phones or accessing secure locations. This is achieved through a process called "liveness" or "anti-spoofing" which judges whether the face presented is genuine or not.
The face presented by other media can be defined as a fake: photo prints of faces, faces on phone screens, silicone masks, 3D human images, etc. This model outputs three concepts:
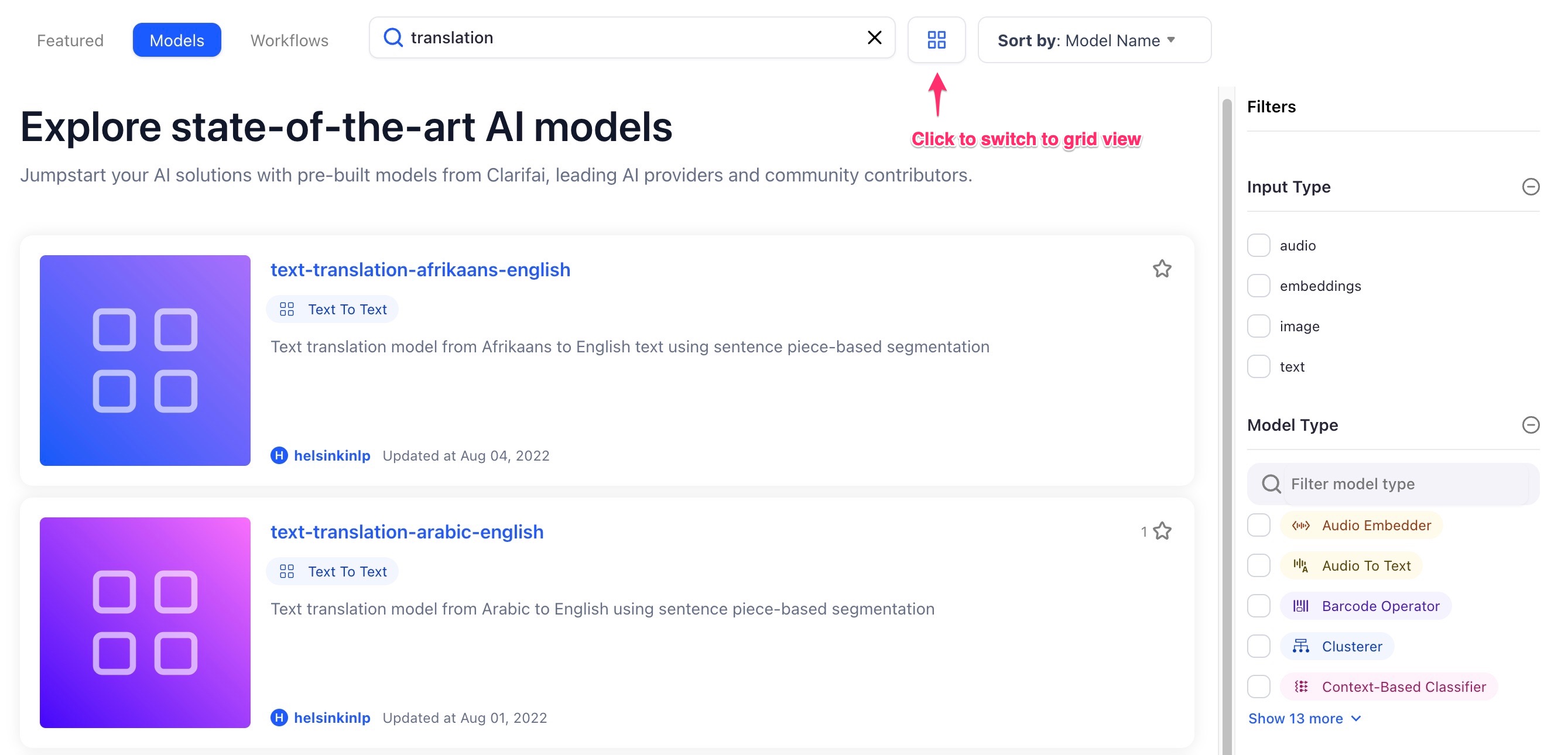
Made major redesign changes on listing pages
We've made major improvements to the look and feel of Clarifai Community! There's a whole new look when navigating the listing pages for models and workflows, we've added new designs and colors for model and workflow icons, and you can now view them in list or grid mode.
In list view:
And in grid view:
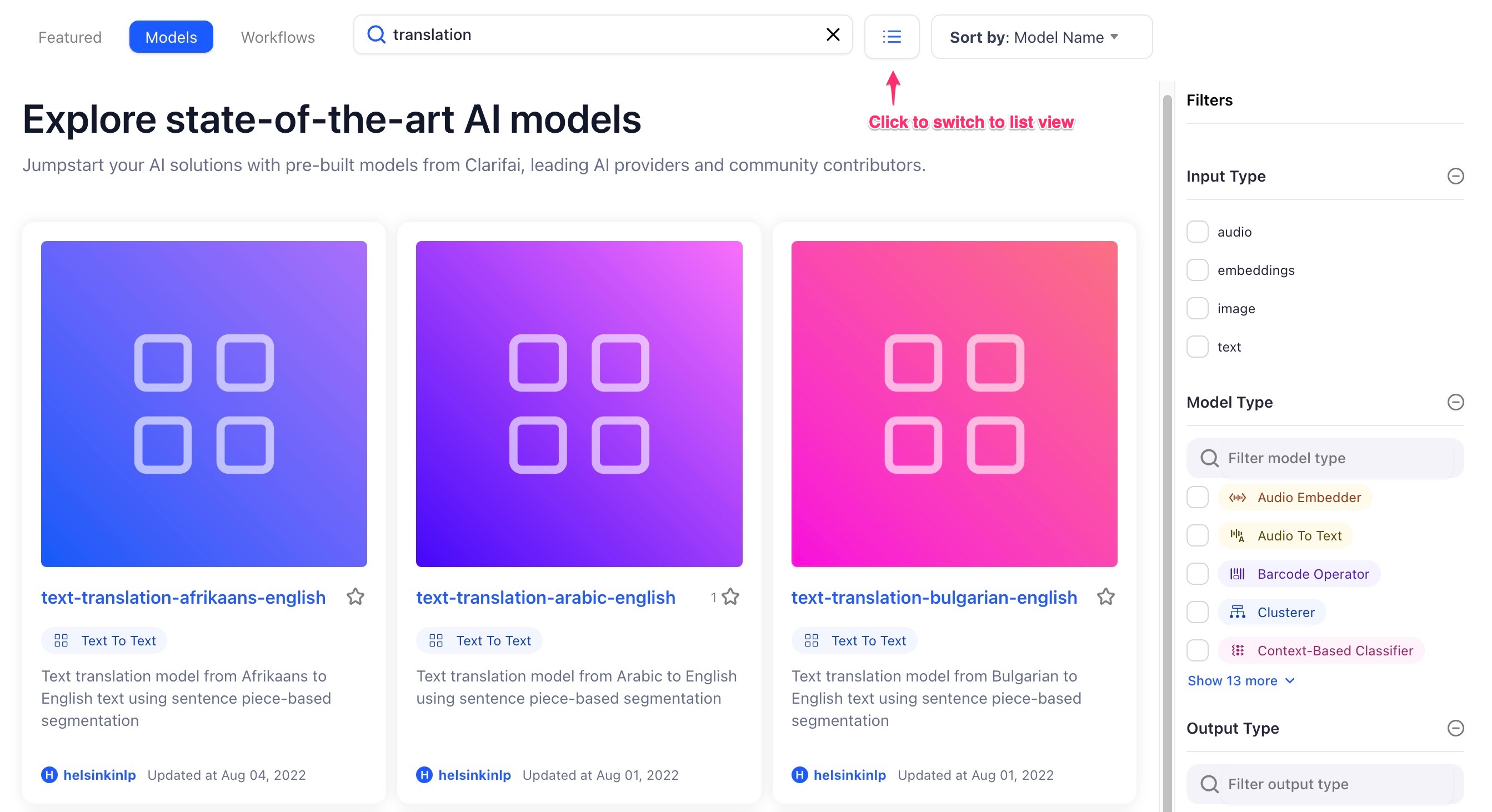
We've also improved the responsiveness of the pages for viewing on mobile devices:
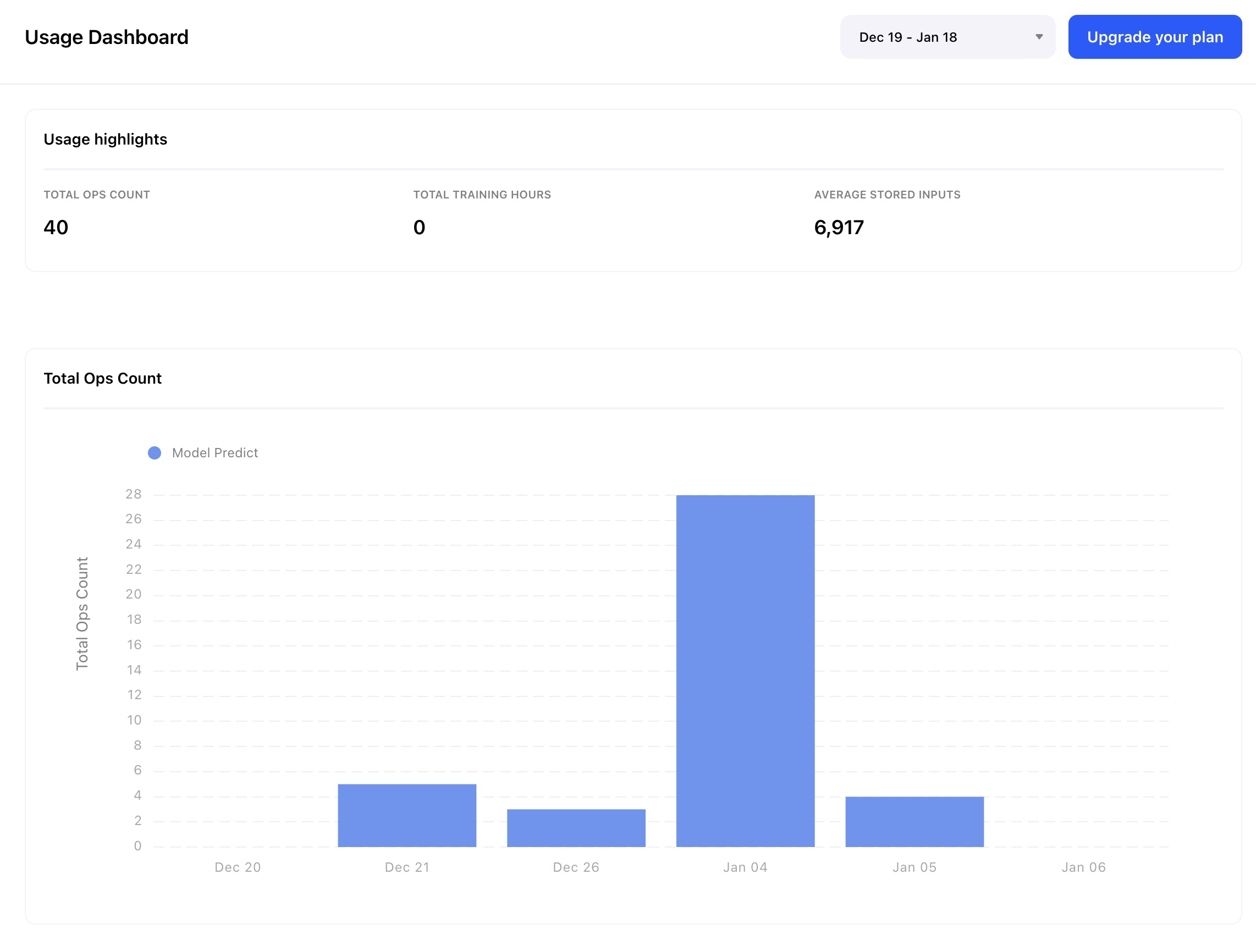
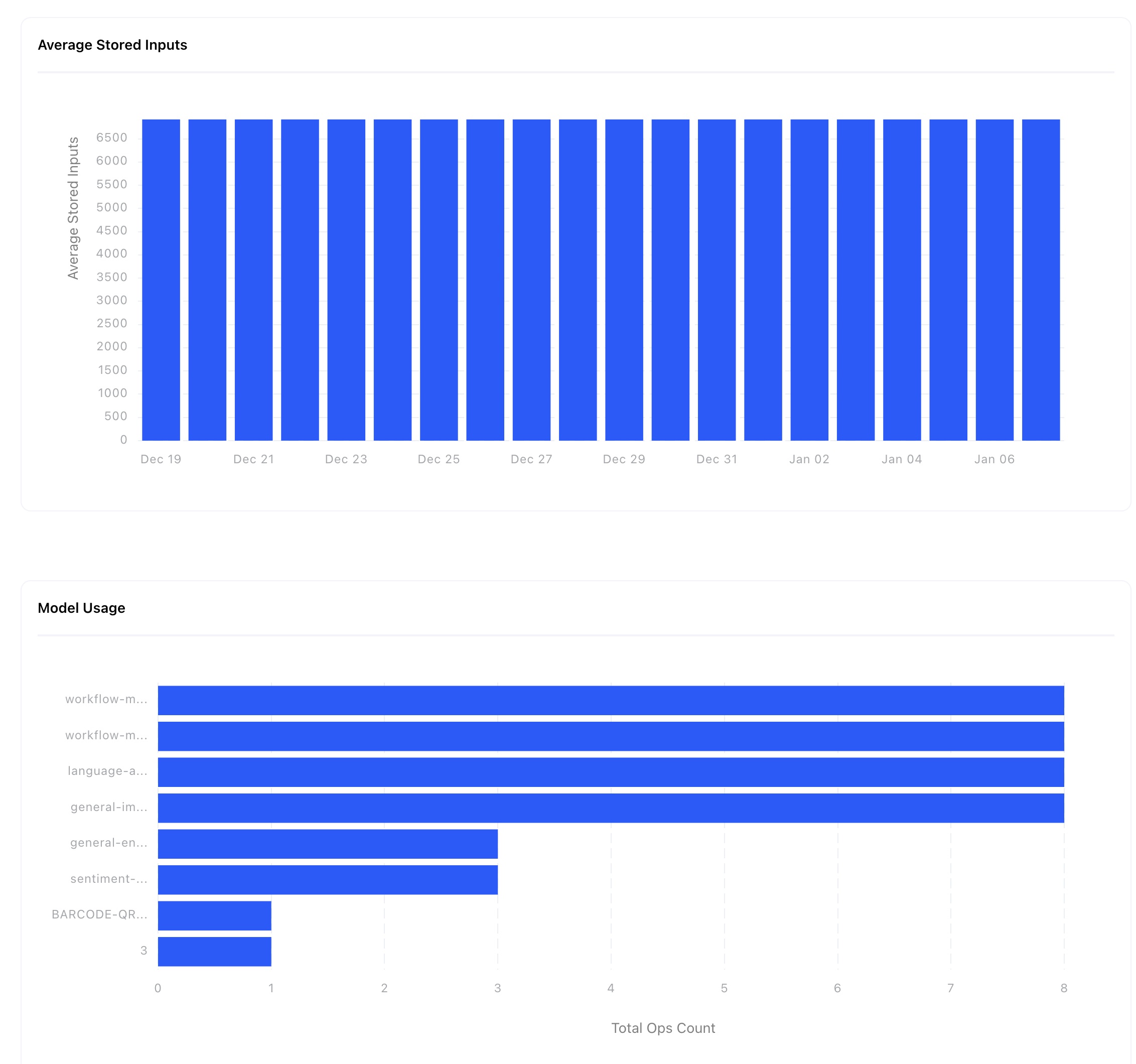
Improvements to the Usage Dashboard
We've replaced “Stored Inputs” with “Average Stored Inputs" and now compute it as an average, not as the total. We've also added the word “Total” to “Training Hours” and “Ops Count.” They are now referred to as “Total Training Hours” and “Total Ops Count” respectively.
Added tooltips to the collapsible sidebar icons
Some of the menus have collapsible sidebars; in the collapsed view on the left sidebar, the menu items are hidden and only the icons are left. We have now added a hover pop-up of the same text we hide to help users understand what each menu item is for.
Stopped showing name and surname on public profiles
Public profiles show a user's name if it's their own account, they are a collaborator of your app, or they are part of your organization. Otherwise, it only shows the account name.
Community & Portal Bug Fixes
- Fixed an issue where collaborators' names showed as "undefined" in several places. Names of app collaborators are now displayed as desired without any issues.
- Fixed an issue where the collapsible left sidebar sometimes did not display all the menu items unless the page was reloaded. All the items of the sidebar are now displayed as desired.
- Fixed an issue where the header items did not display properly on mobile devices. The top navigation bar items are now displayed properly on small screens.
- Fixed an issue where editing a model's params did not show the proper original params. Previously, if you tried editing a model to see or change its parameters, you could find that some of them were set to default values, even if you set them differently during model creation. This is not the case currently as the proper original params are reflected.
Workflow Editor
Made improvements to dynamically render layouts of workflows.
The workflow editor is now able to interpret an entire workflow graph definition and dynamically calculate the proper 2-dimensional coordinates for each of the nodes in the graph.
API
Introduced the Python Utils package
You can now use the collection of small Python functions and classes to make common patterns shorter and easier when interacting with our API.
Exclusion of Some Fields From PostModelOutputs and PostWorkflowResults Prediction Responses
- When using the PostModelOutputs endpoint or the PostWorkflowResults endpoint to make a prediction call, the entire model information, including all hyperparameters, is included for each output in the response. This is extremely verbose and also unnecessary, as the same information appears repeatedly throughout the response. It also impacts network usage, ease of viewing and processing the results and debugging by the user, and other performances.
- Model description, notes and related model info fields are to be excluded from PostModelOutputs and PostWorkflowResults prediction responses. The model and model version ids are still available in the responses. If you need more model info than that available from any of the responses, you can look up the info by model id using the GetModel endpoint.
Critical Updates to Model and Model Version Endpoints (Jan 20, 2023)
Old Behavior
- Previously, using the PostModels endpoint to create a new model also created a placeholder version of the model with user-provided fields. And if the
model_type_id of the model was trainable, then a new ModelVersion was created with UNTRAINED status by default. Otherwise, if the model_type_id was not trainable, then a new ModelVersion was created with TRAINED status.
- Modifying a model's config settings requires using the PatchModels endpoint. It's how you previously changed the info fields, descriptions, notes, metadata for both models and model versions. If you were only patching fields that are informational about the model, and not the model version, a model version was not created. If you were patching a trainable model where the latest model version was trained, and you were only changing the
output_info, a new trained model version was created with the new info. Otherwise, if you were patching a trainable model where the latest model version had not been trained, the created model version was marked as untrained by default. If you were patching an untrainable model type, the new created model version was marked as trained.
- Previously, using the PostModelVersions endpoint automatically, by default, kicked off training the latest untrained model version—even though a user may not intend to train the latest version, which could unnecessarily incur training costs.
- Previously, using the PatchModelVersions endpoint only patched a model versions' visibility, metadata, license, or description—while maintaining the model version's status.
New Behavior
- PostModels will create new models but not create new model versions. This means trainable models that have not yet been trained will require the additional step of calling PostModelVersions—while providing the
*_info fields in the model version—to effect training.
- PostModelVersions will allow users to give information specific to a model version. All the
*_info fields—such as output_info, input_info, train_info, and import_info—will be migrated to the endpoint. This would minimize the confusion and difficulty of maintaining these endpoints. Users will be able patch model specific fields without worrying about model version fields being affected.
- PatchModels will allow users to patch only the model level fields, nothing in the model version. Unnecessary model versions will no longer be created. This allows users to easily track persisted versions.
- PatchModelVersions will be the new way to change most of the model version fields like gettable, metadata, license, description, notes, and
output_info (not including concepts).
API Fixes
- Fixed an issue when the API received Base64 decoded masks. Previously, if you provided a Base64 mask via an HTTP request, it failed to be created. It now works as expected.





