
Artificial intelligence (AI) is no longer just a buzzword; many businesses are struggling to scale models because they lack the right infrastructure. AI infrastructure comprises technologies for computing, data management, networking, and orchestration that work together to train, deploy, and serve models. In this guide, we’ll explore the market, compare top AI infrastructure companies, and highlight new trends that will transform computing. Understanding this space will empower you to make better decisions whether you’re building a startup or modernizing your operations.
AI infrastructure is built for high-compute workloads like training language models and running computer vision pipelines. Traditional servers struggle with large tensor computations and high data throughput. Thus, AI systems rely on accelerators like GPUs, TPUs, and ASICs for parallel processing. Additional components include data pipelines, MLOps platforms, network fabrics, and governance frameworks, ensuring repeatability and regulatory compliance. NVIDIA CEO Jensen Huang coined AI as “the essential infrastructure of our time,” highlighting that AI workloads need a tailored stack.
To train advanced models, teams must coordinate compute resources, storage, and orchestration across clusters. DataOps 2.0 tools handle data ingestion, cleaning, labeling, and versioning. After training, inference services must respond quickly. Without a unified stack, teams face bottlenecks, hidden costs, and security issues. A survey by the AI Infrastructure Alliance shows only 5–10 % of businesses have generative AI in production due to complexity. Adopting a full AI-optimized stack enables organizations to accelerate deployment, reduce costs, and maintain compliance.
The AI infrastructure market is booming. ClearML and the AI Infrastructure Alliance report it was worth $23.5 billion in 2021 and will grow to over $309 billion by 2031. Generative AI is expected to hit $98.1 billion by 2025 and $667 billion by 2030. In 2024, global cloud infrastructure spending reached $336 billion, with half of the growth attributed to AI. By 2025, cloud AI spending is projected to exceed $723 billion.
Generative AI adoption spans multiple sectors:
Big players are investing heavily in AI infrastructure: Microsoft plans to spend $80 billion, Alphabet up to $75 billion, Meta between $60 – 65 billion, and Amazon around $100 billion. However, 96 % of organizations intend to further expand their AI computing power, and 64 % already use generative AI—illustrating the rapid pace of adoption.
The compute layer supplies raw power for AI. It includes GPUs, TPUs, AI ASICs, and emerging photonic chips. Major hardware companies like NVIDIA, AMD, Intel, and Cerebras dominate, but specialized providers—AWS Trainium/Inferentia, Groq, Etched, Tenstorrent—deliver custom chips for specific tasks. Photonic chips promise almost zero energy use in convolution operations. Later sections cover each vendor in more detail.
Major hyperscalers provide all-in-one stacks that combine computing, storage, and AI services. AWS, Google Cloud, Microsoft Azure, IBM, and Oracle offer managed training, pre-built foundation models, and bespoke chips. Regional clouds like Alibaba and Tencent serve local markets. These platforms attract enterprises seeking security, global availability, and automated deployment.
New entrants such as Clarifai, CoreWeave, Lambda Labs, Together AI, and Voltage Park focus on GPU-rich clusters optimized for AI workloads. They offer on-demand pricing, transparent billing, and quick scaling without the overhead of general-purpose clouds. Some, like Groq and Tenstorrent, create dedicated chips for ultra-low-latency inference.
DataOps 2.0 platforms handle data ingestion, classification, versioning, and governance. Tools like Databricks, MLflow, ClearML, and Hugging Face provide training pipelines and model registries. Observability services (e.g., Arize AI, WhyLabs, Credo AI) monitor performance, bias, and drift. Frameworks like LangChain, LlamaIndex, Modal, and Foundry enable developers to link models and agents for complex tasks. These layers are essential for deploying AI in real-world environments.
| Section | Scope | Leaders | Best for | Metrics to compare |
|---|---|---|---|---|
| 1) End-to-End AI Lifecycle & Compute Orchestration | Unified control planes that connect data → models → compute with governance | Clarifai; Run:ai; Anyscale (Ray); Modal; W&B / ClearML / Comet | Enterprises needing governed hybrid/multicloud AI; teams running reasoning-heavy agents & RAG | Tokens/sec; TTFT; $/M-tokens; GPU utilization; queue wait time; SLO adherence; governance coverage |
| 2) Cloud Platforms | Managed cloud AI stacks with proprietary accelerators & data fabrics | AWS (SageMaker, Bedrock, Trainium/Inferentia); Google Cloud (Vertex, TPU); Azure (AML, Foundry); IBM (watsonx); Oracle (OCI) | Teams wanting managed scale, regional presence, compliance | $/GPU-hr or $/TPU-hr; spot capacity; region latency; egress costs; SLA; ecosystem fit |
| 3) Hardware & Chip Innovators | Specialized silicon for training, low-latency inference, energy efficiency | AWS Trainium/Inferentia; Cerebras; Groq; Etched; Tenstorrent; Lightmatter | Labs needing throughput/latency leaps or energy gains; sovereign/novel stacks | Perf/W; tokens/sec @ context; HBM bandwidth; determinism (p95-p99); rack power density |
| 4) AI Networking & Interconnectors | Fabrics & offloads that let clusters scale efficiently | NVIDIA (InfiniBand, NVLink/NVSwitch); Arista; Juniper; NVIDIA BlueField; AMD Pensando; Fungible; Innovium; Lightmatter; Ayar Labs; Celestial AI | Hyperscale training; hybrid clusters; zero-trust multi-tenant | Link BW (e.g., 800 Gb/s); p95 latency; all-reduce efficiency; CPU/DPU offload %; NVMe-oF throughput |
| 5) AI Model & Platform Builders (LLM Platform Influence Layer) | Model labs & OSS that shape hardware roadmaps and orchestration standards | OpenAI; Anthropic; Google DeepMind; Meta; xAI; Mistral; Kimi; GPT-OSS; Llama | Teams aligning infra to reasoning & multimodal roadmaps; OSS-first orgs | Context-length cost; multimodal latency; MoE routing efficiency; eval quality vs cost |
These companies unify data, model, and compute management into a single governed platform—enabling reproducibility, efficiency, and governance across the AI lifecycle.
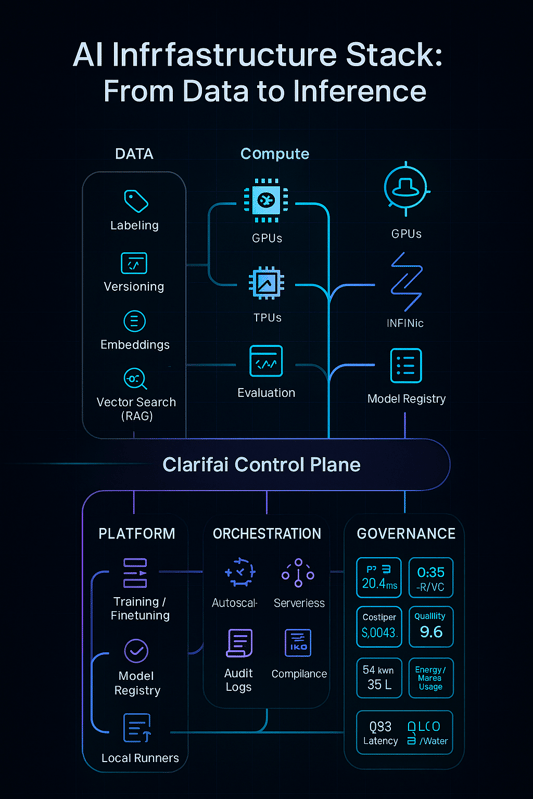
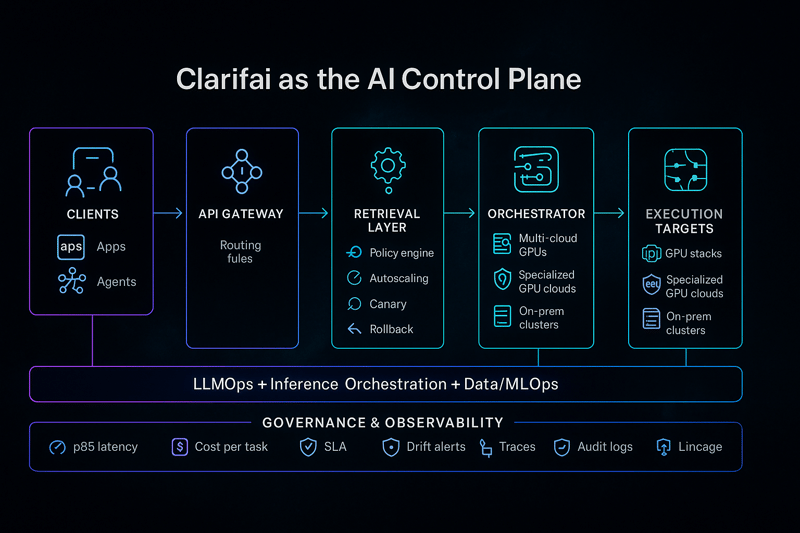
Clarifai is an end-to-end AI lifecycle platform that bridges compute orchestration, model inference, and data/MLOps—all under one unified control plane. Unlike hyperscalers that primarily sell raw compute, Clarifai focuses on intelligent orchestration and cost-optimized reasoning across cloud, on-prem, and edge environments.
Unified AI Control Plane:
Connects data, models, and compute seamlessly across multi-cloud, VPC, or on-prem GPU environments—ensuring interoperability and governance throughout the AI lifecycle.
End-to-End AI Lifecycle:
Supports every stage—from data labeling, vector search, retrieval-augmented generation (RAG), fine-tuning, and evaluation to deployment and monitoring—eliminating the need for brittle integrations or external tools.
GPU Reasoning Engine:
Clarifai’s Reasoning Engine delivers one of the fastest throughputs on GPUs (544 tokens/sec) with a 3.6s time to first answer and $0.16 per million tokens blended cost, making it ideal for agentic workloads that require sustained reasoning over millions of tokens.
Compute Orchestration & Cost Optimization:
Intelligent routing of inference and reasoning workloads to the best-fit GPUs across regions and providers—balancing performance, latency, and cost automatically.
Inference & Deployment Flexibility:
Autoscaling inference endpoints adapt to dynamic workloads.
Local Runners enable air-gapped, low-latency, or edge deployments—ensuring compliance and speed in regulated or real-time environments.
Governance & Enterprise Security:
Built-in approvals, audit logs, and RBAC (Role-Based Access Control) ensure traceability and compliance across teams and projects.
Open Source Model Friendly:
Deploy and run any open-source model (like Llama 3, Mistral, or Mixtral) or your own custom fine-tuned models on Clarifai GPUs with full control and transparency.
Enterprises needing agentic AI infrastructure that scales across hybrid or multi-cloud environments.
Teams running reasoning-heavy LLMs and RAG pipelines with a focus on throughput and cost-efficiency.
Organizations seeking governed, end-to-end AI workflows—from data prep to deployment—without vendor lock-in.
“Clarifai’s value lies in unifying the entire AI lifecycle—data, models, and compute—under one governed infrastructure layer. Its GPU Reasoning Engine and compute orchestration make it one of the fastest and most cost-effective platforms for production-scale agentic AI.”
Run:ai has established itself as a leader in AI compute orchestration, abstracting away the complexity of GPU management through virtualization and dynamic scheduling.
The platform virtualizes GPU clusters across on-prem, cloud, and hybrid environments, allowing multiple users and workloads to share GPUs concurrently—maximizing utilization.
With advanced features like GPU partitioning, auto-scheduling, and fair-share allocation, Run:ai ensures that training, inference, and fine-tuning jobs can run efficiently side by side.
Its deep integration with Kubernetes, Kubeflow, and other MLOps frameworks makes it a natural fit for enterprise-scale research labs and data science teams.
The 2025 release of Run:ai Cloud Fabric adds enhanced multi-tenant governance and usage-based visibility, aligning with enterprises prioritizing accountability and cost predictability.
Best for: Enterprises and labs optimizing GPU utilization, multi-user workflows, and scalable model training.
Built on Ray, the open-source distributed computing framework, Anyscale brings elastic scaling to AI and machine learning workloads—from laptop prototypes to thousands of GPUs in production.
Anyscale enables distributed training, inference, reinforcement learning, and hyperparameter tuning with seamless scaling.
The platform powers some of the world’s most sophisticated AI systems—used by OpenAI, Uber, and Shopify—to manage compute distribution and workload parallelization.
Its Ray Serve module simplifies model deployment, while Ray Tune and Ray Train automate tuning and distributed training pipelines.
Anyscale now supports Ray 3.0, offering improved fault tolerance, checkpointing, and integration with custom hardware accelerators.
Best for: Teams building custom distributed AI systems, agentic workloads, or reinforcement learning environments that demand full control over scaling logic.
Modal redefines how developers access GPUs by providing a serverless AI runtime that eliminates infrastructure management.
Developers can launch inference, training, or batch jobs directly from code—without worrying about provisioning or scaling clusters.
Modal’s cold-start optimization and ephemeral GPU environments allow rapid spin-up for short-lived jobs, ideal for iterative model development and evaluation.
Its fine-grained, pay-per-second billing makes GPU access cost-efficient, especially for startups, small teams, and experimental workloads.
With recent updates, Modal supports multi-GPU and distributed execution, bringing serverless simplicity to large-scale use cases.
Best for: Developers and engineering teams seeking speed, flexibility, and cost-efficient GPU execution—from prototype to production.
These platforms form the observability and experiment tracking backbone of modern AI infrastructure—critical for governance, collaboration, and continuous improvement.
Weights & Biases (W&B) leads in experiment tracking, dataset versioning, and model performance visualization, enabling teams to monitor every training run with precision.
ClearML provides a self-hosted, open alternative with powerful data and pipeline orchestration, ideal for regulated environments or air-gapped deployments.
Comet ML focuses on real-time metrics visualization, parameter management, and collaboration across model lifecycles.
All three integrate natively with Kubernetes, Run:ai, Anyscale, and major cloud providers—bridging the gap between infrastructure utilization and model performance insight.
Best for: Research and production teams managing large-scale ML experimentation, model governance, and performance analytics across hybrid environments.
Run:ai virtualizes GPU infrastructure for multi-tenant orchestration and efficiency.
Anyscale enables scalable, distributed AI workloads built on Ray.
Modal delivers serverless, on-demand GPU compute for agile teams.
W&B, ClearML, and Comet provide the visibility, versioning, and observability layer that connects development to production.
Together, they form the software nervous system of AI infrastructure—turning raw compute into intelligent, adaptive, and measurable pipelines.
“The real power of AI infrastructure lies in orchestration.
Platforms like Clarifai, Run:ai, Anyscale, and Modal transform raw GPU capacity into dynamic compute fabrics, while tools like W&B, ClearML, and Comet ensure that every model iteration is traceable, explainable, and optimized.
These layers close the loop between infrastructure performance and model intelligence—enabling true end-to-end AI operations.”
As AI workloads surge in complexity and scale, the demand for dedicated, high-performance GPU infrastructure has outgrown what traditional hyperscalers alone can provide.
A new generation of specialized GPU cloud and colocation providers has emerged—offering flexible access to dense compute clusters, custom networking, and optimized data pipelines for large-scale training, fine-tuning, and inference.
These providers form the critical mid-layer of the global AI compute ecosystem—bridging hyperscale clouds, private data centers, and open AI research environments.
CoreWeave evolved from cryptocurrency mining to become a prominent GPU cloud provider. It provides on-demand access to NVIDIA’s latest Blackwell and RTX PRO GPUs, coupled with high-performance InfiniBand networking. Pricing can be up to 80 % lower than traditional clouds, making it popular with startups and labs.
Lambda Labs offers developer-friendly GPU clouds with 1-Click clusters and transparent pricing—A100 at $1.25/hr, H100 at $2.49/hr. It raised $480 million to build liquid-cooled data centers and earned SOC2 Type II certification.
Expert Advice
Voltage Park, backed by Andreessen Horowitz (a16z), is redefining how open AI developers access large-scale GPU clusters.
The company operates tens of thousands of NVIDIA H100 GPUs, arranged in ultra-dense, low-latency clusters purpose-built for foundation model training and agentic inference workloads.
Unlike traditional clouds, Voltage Park offers bare-metal-level access and transparent pricing, aligning with the needs of open-source AI labs, startups, and research collectives.
Its infrastructure is optimized for distributed training and parallelized inference, with full support for InfiniBand interconnects, NVLink, and liquid-cooled racks.
Recent partnerships with Mistral, Hugging Face, and EleutherAI demonstrate its commitment to supporting the open AI ecosystem rather than locking users into proprietary services.
Why it matters: Voltage Park’s mission to democratize access to hyperscale compute makes it a cornerstone of the global open AI infrastructure movement.
Best for: Large-scale model developers, AI startups, and enterprises seeking dense, cost-efficient GPU clusters for training and inference at scale.
Equinix and Digital Realty power the physical backbone of global AI infrastructure. These data center leaders enable enterprises to deploy private AI clusters, colocate GPU servers, or connect directly to cloud and specialized GPU providers.
Both offer carrier-neutral colocation, direct interconnects to hyperscalers like AWS, Azure, and Google Cloud, and proximity to major GPU regions for ultra-low latency.
Their bare-metal and private cage options are ideal for organizations building sovereign AI infrastructure—balancing data sovereignty, compliance, and security with scalability.
Equinix Metal and Digital Realty ServiceFabric now offer automated provisioning for GPU resources, enabling hybrid orchestration through platforms like Clarifai, Run:ai, or NVIDIA DGX Cloud.
Both companies are investing heavily in liquid cooling, renewable energy sourcing, and AI-ready network fabrics to support next-gen compute sustainability goals.
Why it matters: These providers form the foundation layer for private, sovereign, and hybrid AI compute strategies—linking regulated industries to the global AI fabric.
Best for: Regulated enterprises, financial institutions, and public-sector organizations building compliant, hybrid AI data centers with direct cloud and GPU access.
The true bottleneck in large-scale AI training isn’t always compute—it’s data throughput.
That’s where Vast Data, WEKA, and Lightbits come in: they build the data infrastructure that keeps GPUs fully utilized, ensuring models are continuously fed with data at memory speed.
Vast Data delivers unified storage for AI and HPC, combining NVMe-over-Fabric performance with scalable object storage economics—ideal for training massive LLMs and multi-modal pipelines.
WEKA provides a parallel file system with sub-millisecond latency, designed specifically for GPU clusters—its Data Platform for AI is now adopted by NVIDIA DGX SuperPOD and leading model labs.
Lightbits focuses on software-defined NVMe storage, offering low-latency block access for high-performance inference and fine-tuning workloads, while optimizing I/O patterns across distributed GPUs.
Collectively, these companies eliminate data starvation, improving GPU efficiency, checkpointing reliability, and scaling throughput across training pipelines.
Why it matters: As AI workloads scale to trillions of tokens, data I/O throughput becomes as critical as compute power. These providers ensure every GPU cycle counts.
Best for: Data-intensive AI workloads such as foundation model training, multi-modal search, and real-time inference pipelines.
“The future of AI compute depends as much on how infrastructure is delivered as on how fast it runs.
Specialized GPU providers like Voltage Park, Equinix, Digital Realty, Vast Data, and WEKA are redefining performance economics—enabling flexible, sovereign, and data-saturated AI operations.
Paired with orchestration layers like Clarifai and Run:ai, they form the dynamic backbone of modern AI infrastructure—one built for both speed and sustainability.”
AWS excels at AI infrastructure. SageMaker simplifies model training, tuning, deployment, and monitoring. Bedrock provides APIs to both proprietary and open foundation models. Custom chips like Trainium (training) and Inferentia (inference) offer excellent price-performance. Nova, a family of generative models, and Graviton processors for general compute add versatility. The global network of AWS data centers ensures low-latency access and regulatory compliance.
Expert Opinions
At Google Cloud, Vertex AI anchors the AI stack—managing training, tuning, and deployment. TPUs accelerate training for large models such as Gemini and PaLM. Vertex integrates with BigQuery, Dataproc, and Datastore for seamless data ingestion and management, and supports pre-built pipelines.
Microsoft Azure AI offers AI services through Azure Machine Learning, Azure OpenAI Service, and Foundry. Users can choose from NVIDIA GPUs, B200 GPUs, and NP-series instances. The Foundry marketplace introduces a real-time compute market and multi-agent orchestration. Responsible AI tools help developers evaluate fairness and interpretability.
Experts Highlight
IBM Watsonx offers capabilities for building, governing, and deploying AI across hybrid clouds. It provides a model library, data storage, and governance layer to manage the lifecycle and compliance. Oracle Cloud Infrastructure delivers AI-enabled databases, high-performance computing, and transparent pricing.
Expert Opinions
While U.S.-based hyperscalers dominate the global AI infrastructure landscape, regional and edge providers are playing a growing role—especially in data sovereignty, localized optimization, and low-latency inference. These players often blend specialized hardware with edge compute orchestration, enabling AI workloads to run closer to users, sensors, and devices.
AI Stack & Chips: Alibaba’s in-house Hanguang 800 AI chip powers large-scale model training and inference optimized for Mandarin and APAC-centric NLP workloads.
Ecosystem Strength: Its PAI (Platform for AI) and MaxCompute tools serve as the backbone for enterprises deploying AI at scale in regulated Asian markets.
Regional Advantage: Deep integration with Chinese compliance frameworks and language-specific models makes Alibaba a strong choice for localized AI services.
Hardware & Frameworks: Tencent leverages NeuroPilot and custom accelerators to deliver efficient inferencing, especially for speech and vision models used in gaming and entertainment ecosystems.
Developer Ecosystem: Through Tencent AI Lab, it supports model training, deployment, and monitoring tailored to real-time social, gaming, and streaming applications.
Strategic Edge: Strong presence in Southeast Asia and localized data centers position Tencent Cloud as a dominant regional alternative to U.S. providers.
AI Hardware: Huawei’s Ascend AI processors and Atlas hardware line deliver high-performance training and inference optimized for both cloud and edge environments.
Software Stack: Its MindSpore framework competes directly with PyTorch and TensorFlow, offering tight hardware-software coupling.
Geopolitical Edge: Often chosen by government and telco clients seeking sovereign AI infrastructure that avoids Western cloud dependencies.
Edge Compute Focus: Akamai’s EdgeWorkers platform allows AI and inference models to run at the CDN edge—reducing latency by processing requests closer to the user.
Use Cases: Ideal for IoT analytics, fraud detection, and personalized content delivery, where milliseconds matter.
Strength: Its distributed edge network and developer APIs make it one of the most practical edge inference options at scale.
Real-Time Edge AI: Fastly’s Compute@Edge enables low-latency model execution for real-time applications such as cybersecurity, streaming analytics, and interactive AI assistants.
Developer-Focused: Strong tooling for WASM-based (WebAssembly) AI inference pipelines allows developers to deploy lightweight models with near-instant cold starts.
Differentiator: Prioritizes performance transparency and open tooling over proprietary lock-ins.
Edge AI & Serverless: Cloudflare’s Workers AI runs open-source models at the edge, with vector database integration for lightweight RAG and embeddings use cases.
Global Reach: With data centers in 310+ cities, it offers one of the largest distributed inference fabrics globally.
Positioning: Ideal for developers needing API-first, low-latency AI experiences without provisioning infrastructure.
Embedded AI & IoT: Specializes in TinyML and edge inference for resource-constrained devices like sensors and microcontrollers.
Tooling: Offers a full workflow for data collection, model training, and deployment directly on edge hardware.
Use Case Focus: Perfect for industrial automation, wearables, and smart city applications where real-time decision-making happens locally.
Regional and edge providers are redefining AI infrastructure by combining sovereign compute, localized optimization, and ultra-low latency.
While hyperscalers dominate scale and integration, these platforms excel where regulation, proximity, and performance intersect—forming a critical layer in the emerging distributed AI infrastructure stack.
NVIDIA leads the market with its H100, B100, and upcoming Blackwell GPUs. These chips power many generative AI models and data centers. DGX systems bundle GPUs, networking, and software for optimized performance. Features such as tensor cores, NVLink, and fine-grained compute partitioning support high-throughput parallelism and better utilization.
Expert Advice
AMD competes with MI300X and MI400 GPUs, focusing on high-bandwidth memory and cost efficiency. Intel develops Gaudi accelerators and Habana Labs technology while integrating AI features into Xeon processors.
While GPUs dominate the AI landscape, a new wave of specialized chip innovators is reshaping the performance, cost, and energy profile of large-scale AI infrastructure. These companies focus on purpose-built silicon—optimized for specific phases of the AI lifecycle like training, inference, or reasoning. Their architectures challenge the GPU’s monopoly by delivering greater throughput, deterministic latency, or radical efficiency gains.
AWS has emerged as a legitimate silicon innovator through its Trainium and Inferentia families—custom chips designed to make AI compute both affordable and sustainable.
Trainium (now in its second generation) targets large-scale training workloads, offering competitive FLOPs-per-dollar and improved energy efficiency.
Inferentia powers production inference with up to 10× lower latency and cost versus comparable GPU instances.
Together, they form the foundation of AWS’s vertical AI stack, tightly integrated with SageMaker and Bedrock for streamlined training-to-deployment workflows.
Best for: Enterprises seeking cloud-native acceleration without dependency on third-party GPUs.
Cerebras redefined chip design with its Wafer-Scale Engine (WSE)—a single silicon wafer transformed into one massive processor.
The WSE-3 packs nearly 900,000 AI-optimized cores and 4 trillion transistors, offering 125 petaflops of compute per chip.
Its architecture minimizes data movement and parallelizes massive tensor operations, making it ideal for LLM training at unprecedented scale.
Cerebras’s modular CS-3 systems and Condor Galaxy supercomputers deliver cloud-accessible AI training power that rivals hyperscale GPU clusters.
Best for: Research labs, government, and enterprise teams scaling large language and foundation model training.
Groq’s Language Processing Unit (LPU) takes a radically different path—optimized not for peak FLOPs, but for deterministic, ultra-low-latency inference.
Its architecture uses static dataflow scheduling and SRAM-based compute to achieve consistent sub-millisecond response times.
These traits make Groq a standout for real-time inference, powering conversational agents, streaming analytics, and autonomous systems.
Benchmarks show token generation speeds exceeding 240 tokens/sec on Llama-2–70B, underscoring its suitability for agentic AI workloads.
Best for: Developers and enterprises deploying interactive, latency-critical AI systems.
Etched is pioneering transformer-specific ASICs, optimized purely for inference—no GPUs, no general-purpose overhead.
Its flagship Sohu chip is built from the ground up to accelerate transformer layers, offering massive token throughput and dramatic energy savings.
By focusing exclusively on one model architecture, Etched can achieve order-of-magnitude efficiency gains for LLM inference workloads.
While still pre-deployment, the company represents the next generation of inference-optimized silicon.
Best for: AI companies seeking dedicated inference hardware for LLM APIs and cloud deployment.
Founded by legendary chip designer Jim Keller, Tenstorrent is blending RISC-V CPU IP with AI acceleration cores to build scalable, open compute platforms.
Its Tensix architecture uses many-core parallelism for both training and inference workloads.
The company’s Blackhole accelerator and Ascalon CPU are central to its vision of decentralized AI data centers—combining open hardware with open instruction sets.
Tenstorrent also licenses its IP to chipmakers, positioning itself as both a hardware innovator and ecosystem enabler.
Best for: Organizations building custom or sovereign AI infrastructure leveraging open hardware standards.
Lightmatter is reimagining the physics of computation.
Its photonic chips like Envise perform matrix multiplications using light instead of electrons, drastically reducing heat and energy use.
Complementary technologies like Passage, its optical interconnect, enable faster chip-to-chip communication for large AI clusters.
As models grow larger and energy constraints tighten, photonic computing offers a glimpse into the post-transistor era of AI acceleration.
Best for: Future-facing AI data centers prioritizing energy efficiency and high-bandwidth model scaling.
As models scale from billions to trillions of parameters, AI networking has become the silent performance driver of modern infrastructure. High-speed, low-latency interconnects determine how efficiently data, gradients, and activations move across compute clusters. In this new era of distributed training and inference, networking hardware and software are just as crucial as GPUs themselves.
NVIDIA dominates the AI interconnect layer through its InfiniBand and NVLink technologies—critical for connecting tens of thousands of GPUs into one logical supercomputer.
InfiniBand NDR and XDR deliver up to 800 Gb/s throughput with single-digit microsecond latency, enabling seamless synchronization for LLM training clusters.
NVLink Switch Systems connect GPUs directly within and across nodes, reducing CPU bottlenecks and improving collective communication efficiency.
These innovations underpin nearly every hyperscale training run—from GPT-4 to Claude 3—and are defining the standard for AI fabric design.
Best for: Large-scale training clusters requiring deterministic, ultra-high-bandwidth GPU-to-GPU communication.
Enterprise AI data centers increasingly depend on Ethernet-based fabrics from Arista and Juniper that combine 400 GbE/800 GbE switching, RDMA over Converged Ethernet (RoCE), and advanced telemetry for real-time performance tuning.
Arista’s 7800R3 and Juniper’s QFX5700 platforms are optimized for AI East-West traffic patterns, delivering scalable throughput and congestion-aware routing.
These systems bring cloud-grade networking to enterprise and hybrid AI deployments, offering a cost-effective alternative to InfiniBand.
Best for: Enterprises building multi-tenant AI clusters or hybrid GPU farms balancing cost, scale, and performance.
Data-intensive AI workloads increasingly offload control tasks—like encryption, storage management, and virtualization—to Data Processing Units (DPUs).
AMD Pensando DPUs and NVIDIA BlueField-3 offload networking and security, freeing GPU and CPU cycles for computation.
This shift enables zero-trust AI clusters with micro-segmentation and hardware-level isolation, critical for regulated or multi-tenant environments.
Best for: Secure, high-throughput environments needing hardware-accelerated network virtualization and storage access.
Companies like Fungible (now part of Microsoft) and Innovium are pioneering data-centric networking, reducing the overhead between storage arrays and compute nodes.
Their data-path acceleration and NVMe-over-Fabric support drastically lower latency in training data streaming, which can otherwise throttle model throughput.
Best for: Organizations training models on massive, distributed datasets where I/O bottlenecks limit scalability.
The next frontier lies in optical networking—using light instead of electrons to transfer data.
Companies like Lightmatter, Ayar Labs, and Celestial AI are developing photonic interconnects that enable terabit-scale bandwidth with negligible energy loss.
These technologies could soon replace electrical switch fabrics, allowing exascale AI systems to operate with lower power and higher stability.
Best for: Future-ready data centers pursuing energy-efficient, high-bandwidth AI fabrics.
AI networking is now a core determinant of cluster efficiency and scalability.
InfiniBand leads hyperscale performance, while Ethernet-based fabrics from Arista and Juniper bring flexibility and cost balance.
DPUs and SmartNICs offload infrastructure overhead, unlocking higher utilization.
Photonic interconnects signal the next leap toward exascale, sustainable AI compute.
“AI networking has quietly become the heartbeat of large-model infrastructure.
The transition from GPU-bound bottlenecks to fabric-optimized clusters is transforming training economics.
As optical and dataflow interconnects mature, the network will no longer just connect AI—it will be the AI.”
Even though AI infrastructure begins with silicon, networking, and compute orchestration, it’s the AI model builders—the foundation model labs and open-source communities—that are reshaping hardware roadmaps and orchestration standards.
This LLM Platform Influence Layer drives the direction of the entire stack: how chips are designed, clusters are built, and reasoning engines are optimized.
In short, models now dictate infrastructure, not the other way around.
The world’s most advanced model labs—OpenAI, Anthropic, Google DeepMind, Meta AI, and xAI—have become de facto infrastructure architects through the scale of their compute requirements.
Hardware demand as a design signal:
Massive training runs for GPT-4, Claude 3, and Gemini 2.0 have directly shaped the evolution of NVIDIA’s A100 → H100 → Blackwell B200 roadmap, forcing chipmakers to prioritize memory bandwidth, interconnect density, and tensor-core scaling over general-purpose performance.
Cluster topology innovation:
Multi-trillion parameter models require ultra-dense GPU clusters with optimized NVLink/NVSwitch topologies, InfiniBand fabrics, and liquid cooling—pushing hyperscalers to rethink power and thermal design.
Orchestration feedback loop:
The training demands of model labs have inspired new orchestration paradigms—pipeline parallelism, Mixture-of-Experts (MoE) routing, and gradient checkpointing—which in turn inform how compute orchestration layers like Clarifai, Run.ai, and Modal intelligently allocate resources across GPU pools.
Why it matters: The largest AI labs are effectively co-designing future silicon and data center blueprints, dictating both hardware evolution and orchestration intelligence.
Parallel to the hyperscaler labs, open-source model developers like Mistral, Kimi, Llama, and GPT-OSS are shaping a different kind of infrastructure revolution—one driven by accessibility, modularity, and openness.
Efficient model architectures:
Mistral’s Mixtral 8×7B and Mistral 7B highlight a shift toward smaller, more efficient LLMs that deliver competitive reasoning quality at lower compute cost.
This trend favors distributed GPU clusters and dynamic scaling, rather than static monolithic superclusters.
Open inference standards:
Frameworks like vLLM, TGI, and TensorRT-LLM are setting new baselines for open, hardware-agnostic inference performance.
As a result, infrastructure providers are optimizing for runtime interoperability, ensuring that workloads run seamlessly across AMD, NVIDIA, and custom accelerators.
Decentralized AI training:
Projects such as GPT-OSS and Kimi enable collaborative model development across distributed compute environments, fueling demand for multi-cloud orchestration layers that manage heterogeneous infrastructure.
Why it matters: The open-source wave is forcing AI infrastructure to become modular, interoperable, and community-driven—reducing lock-in and expanding global access to LLM-scale compute.
AI is evolving from predictive text generation to reasoning and multi-modal understanding—a transformation that is redefining what infrastructure must deliver.
Reasoning-focused compute:
Modern workloads involve contextual memory, logic chaining, and multi-turn deliberation—requiring long-context inference and adaptive orchestration.
Platforms like Clarifai are at the forefront with their GPU Reasoning Engine, achieving 544 tokens/sec throughput, 3.6s time to first answer, and $0.16 per million tokens blended cost.
This combination of speed, cost-efficiency, and auto-scaling reliability makes reasoning workloads viable for agentic AI systems at production scale.
Multi-modal infrastructure:
Models such as GPT-4o, Gemini 2.0, and Claude 3 Opus process text, image, audio, and video in unified architectures. This demands heterogeneous compute pipelines—combining GPUs, TPUs, and NPUs for different modalities.
It’s driving a new era of infrastructure composability, where orchestration platforms manage multi-modal dataflows end-to-end.
Why it matters: As reasoning and multi-modal AI take center stage, infrastructure must evolve from simple model hosting to dynamic reasoning orchestration—balancing speed, latency, and cost intelligently.
Model labs are driving hardware design and influencing chip roadmaps.
Open-source LLM developers are pushing for modular, interoperable infrastructure.
Reasoning-centric workloads demand intelligent orchestration and adaptive compute scheduling.
Together, these trends form the LLM Platform Influence Layer—the connective tissue between AI innovation and infrastructure design.
“The future of AI infrastructure is being co-authored by the models themselves.
As reasoning, context, and multi-modality become central to AI performance, the physical and logical layers of compute will increasingly adapt to model behavior.
In this ecosystem, platforms like Clarifai—which unify data, orchestration, and reasoning—represent the natural convergence point between model intelligence and infrastructure efficiency.”
DataOps oversees data gathering, cleaning, transformation, labeling, and versioning. Without robust DataOps, models risk drift, bias, and reproducibility issues. In generative AI, managing millions of data points demands automated pipelines. Bessemer calls this DataOps 2.0, emphasizing that data pipelines must scale like the compute layer.
After deployment, models require continuous monitoring to catch performance degradation, bias, and security threats. Tools like Arize AI and WhyLabs track metrics and detect drift. Governance platforms like Credo AI and Aporia ensure compliance with fairness and privacy requirements. Observability grows critical as models interact with real-time data and adapt via reinforcement learning.
LangChain, LlamaIndex, Modal, and Foundry allow developers to stitch together multiple models or services to build LLM agents, chatbots, and autonomous workflows. These frameworks manage state, context, and errors. Clarifai’s platform offers built-in workflows and compute orchestration for both local and cloud environments. With Clarifai’s Local Runners, you can train models where data resides and deploy inference on Clarifai’s managed platform for scalability and privacy.
Having cutting-edge hardware is essential. Providers should offer latest GPUs or specialized chips (H100, B200, Trainium) and support large clusters. Compare network bandwidth (InfiniBand vs. Ethernet) and memory bandwidth because transformer models are memory-bound. Scalability depends on a provider’s ability to quickly expand capacity across regions.
Hidden expenses can derail projects. Many hyperscalers have complex pricing models based on compute hours, storage, and egress. AI-native clouds like CoreWeave and Lambda Labs stand out with simple pricing. Consider reserved capacity discounts, spot pricing, and serverless inference to minimize costs. Clarifai’s pay-as-you-go model auto-scales inference for cost optimization.
Performance varies across hardware generations, interconnects, and software stacks. MLPerf benchmarks offer standardized metrics. Latency matters for real-time applications (e.g., chatbots, self-driving cars). Specialized chips like Groq and Sohu achieve microsecond-level latencies. Evaluate how providers handle bursts and maintain consistent performance.
AI’s environmental impact is significant:
Choose providers committed to renewable energy, efficient cooling, and carbon offsets. Clarifai’s ability to orchestrate compute on local hardware reduces data transport and emissions.
AI systems must protect sensitive data and follow regulations. Ask about SOC2, ISO 27001, and GDPR certifications. 55 % of businesses report increased cyber threats after adopting AI, and 46 % cite cybersecurity gaps. Look for providers with encryption, granular access controls, audit logging, and zero-trust architectures. Clarifai offers enterprise-grade security and on-prem deployment options.
Choose providers compatible with popular frameworks (PyTorch, TensorFlow, JAX), container tools (Docker, Kubernetes), and hybrid deployments. A broad partner ecosystem enhances integration. Clarifai’s API interoperates with external data sources and supports REST, gRPC, and Edge run times.
AI infrastructure consumes huge amounts of resources. Data centers used 460 TWh of electricity in 2022 and may surpass 1,050 TWh by 2026. Training GPT-3 used 1,287 MWh and emitted 552 tons of CO₂. Inference consumes five times more electricity than a typical web search. Cooling also demands around 2 liters of water per kilowatt-hour.
Data centers adopt energy-efficient chips, liquid cooling, and renewable power. HPE’s fanless liquid-cooled design reduces electricity and noise. Photonic chips eliminate resistance and heat. Companies like Iren and Lightmatter build data centers tied to renewable energy. The ACEEE warns that AI data centers could use 9 % of U.S. electricity by 2030, advocating for energy-per-AI-task metrics and grid-aware scheduling.

As Moore’s Law slows, scaling compute becomes difficult. Memory bandwidth now limits transformer training. Techniques like Ring Attention and KV-cache optimization reduce compute load. Mixture-of-Experts distributes work across multiple experts, lowering memory needs. Future GPUs will feature larger caches and faster HBM.
Building AI infrastructure is extremely capital-intensive. Only large tech firms and well-funded startups can build chip fabs and data centers. Geopolitical tensions and export restrictions create supply chain risks, delaying hardware and driving the need for diversified architecture and regional production.
Stakeholders demand explainable AI, but many providers keep performance data proprietary. Openness is difficult to balance with competitive advantage. Vendors are increasingly providing white-box architectures, open benchmarks, and model cards.
Emerging state-space models and transformer variants require different hardware. Startups like Etched and Groq build chips tailored for specific use cases. Photonic and quantum computing may become mainstream. Expect a diverse ecosystem with multiple specialized hardware types.
Agent-based architectures demand dynamic orchestration. Serverless GPU backends like Modal and Foundry allocate compute on-demand, working with multi-agent frameworks to power chatbots and autonomous workflows. This approach democratizes AI development by removing server management.
Governance covers security, privacy, ethics, and regulatory compliance. AI providers must implement encryption, access controls, and audit trails. Frameworks like SOC2, ISO 27001, FedRAMP, and the EU AI Act ensure legal adherence. Governance also demands ethical considerations—avoiding bias, ensuring transparency, and respecting user rights.
Perform risk assessments considering data residency, cross-border transfers, and contractual obligations. 55 % of businesses experience increased cyber threats after adopting AI. Clarifai helps with compliance through granular roles, permissions, and on-premise options, enabling safe deployment while reducing legal risks.
AI infrastructure is evolving rapidly as demand and technology progress. The market is shifting from generic cloud platforms to specialized providers, custom chips, and agent-based orchestration. Environmental concerns are pushing companies toward energy-efficient designs and renewable integration. When evaluating vendors, organizations must look beyond performance to consider cost transparency, security, governance, and environmental impact.
Q1: How do AI infrastructure and IT infrastructure differ?
A: AI infrastructure uses specialized accelerators, DataOps pipelines, observability tools, and orchestration frameworks for training and deploying ML models, whereas traditional IT infrastructure handles generic compute, storage, and networking.
Q2: Which cloud service is best for AI workloads?
A: It depends on the needs. AWS offers the most custom chips and managed services; Google Cloud excels with high-performance TPUs; Azure integrates seamlessly with business tools. For GPU-heavy workloads, specialized clouds like CoreWeave and Lambda Labs may provide better value. Compare compute options, pricing transparency, and ecosystem support.
Q3: How can I make my AI deployment more sustainable?
A: Use energy-efficient hardware, schedule jobs during periods of low demand, employ Mixture-of-Experts or state-space models, partner with providers investing in renewable energy, and report carbon metrics. Running inference at the edge or using Clarifai’s local runners reduces data center usage.
Q4: What should I look for in start-up AI clouds?
A: Seek transparent pricing, access to the latest GPUs, compliance certifications, and reliable customer support. Understand their approach to demand spikes, whether they offer reserved instances, and evaluate their financial stability and growth plans.
Q5: How does Clarifai integrate with AI infrastructure?
A: Clarifai provides a unified platform for dataset management, annotation, model training, and inference deployment. Its compute orchestrator connects to multiple cloud providers or on-prem servers, while local runners enable training and inference in controlled environments, balancing speed, cost, and compliance.




