Face alignment is the process of accurately localizing the set of nodal points that defines the shape of the face when the algorithm is provided with RGB or grayscale images. These nodal points correspond to facial features such as nose, eyes, lips, etc. The common approach for face recognition is to treat it as an object. However, this assumption holds only when the front of the face is considered. As the face orientation varies from frontal, the algorithms are unable to recognize the face. One option is to employ 3D, however, it requires special sensors for imaging as well as multiple images and controlled illumination which is normally not available in real life scenarios.
The prior solutions available for face recognition are deformable part-based models i.e. shape model, appearance model, and motion model which works well with frontal images only.
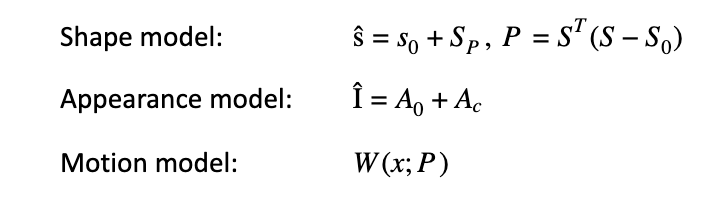
Another method that was used for face recognition was regression and cascaded regression. In this approach, the goal was to learn a set of certain regression models that will approach the location of the nodal points in three steps, where at each step we will make a correction in the previous estimation.
Another method is using 2D heat-maps in Convolutional neural networks. For a certain point corresponding to some facial feature such as an eye, one approach is to isolate the region of interest (ROI). Another approach is multiple picks which are interpretable for various locations and regions thus applicable to different facial orientations.
Encoder and decoder architectures coupled with heat map-based regression using fully convolutional networks are the basis for the aforementioned face recognition methods. The new improved architecture has been proposed by researchers such as HRNet, CU-Net, and Feature Adaptation Networks. By now, face alignment performance is approaching saturation.
A blurred or low-resolution image cannot be reproduced to original with 100% confidence, however, algorithms can be used to fine-tune and hallucinate the images to clarify it to some extent. The application of face-super resolution is not only in surveillance but there is also a growing interest in upgrading the presently available low-resolution content to 4K or 8K. The conventional algorithms use transposed convolutional layers which shuffles the pixels by sacrificing the number of channels over a special dimension. However, the output using this method is still blur and not of human-perceivable quality. Further improvements can be made by training a neural network using the GT database of images and then calculating L1 or L2 loss between the images generated by the neural network and transposed convolutional layer. However, for certain images, the GT image database may not work. Moreover to improve the resolution of a blurred image using a high-quality image is of no use in the case where the high-quality images are not available.
Researchers have proposed an alternative solution that uses cascading frameworks. The high-level face correspondence estimation and low-level face hallucination are complementary and can be alternatively refined by getting guidance from each other. As shown in the figure below, the "common branch" produces hallucinations from low image resolution while the "high-frequency branch" super-resolved faces with additional high-frequency prior.
In order to resolve the problem of alignment in the low-resolution image, the technique described earlier in this article (using heat-maps) can be integrated with the cascading super-resolution as shown in the following figure:
Another approach is to “downsample” the images to create a parent dataset with a low resolution that matches the distribution of real ones. To achieve these first images from the dataset are selected and using neural networks they are "downsampled" into low-resolution images that match the real ones. Finally, the real images are then compared and progressively improved using the same neural network as shown in the following figure:
Following are the “downsampling” qualitative results for different architectures:
Face recognition has large scale applications in mobile devices as well as in mass surveillance. The face recognition problem is best handled when treating it as a “vanilla classification problem” where each identity from a training set forms a new class. Given a backbone network ϕ and input image i a low dimensional embedding is produced xi . When It is projected using a linear layer W and bias b and passed through softmax it can generate onehot(yi) where 1 is target identity and 0 is the rest of it as shown in the figure.
The above architecture suffices for a closed set of face recognition problem, however, it is proposed to use a more open set protocol where testing and training are disjoined. Recent research has shown that a softmax loss is referred to as cosine loss by actually normalizing the buffer features and the vectors moving along with the variations as shown in the following figure:
In the above figure, S is the scaling factor used to ensure convergence.
A better approach is the introduction of “ARCFACE” which uses the arccosine function to calculate the angle between the current feature and the target weight as shown in the following figure:
Summing up, the latest research has shown a pre-trained face alignment network (FAN) to use with face recognition. The method integrates features from FAN and faces recognition network (FRN) as shown in the following figure:
The problem here arises is high GPU usage. The following section addresses this problem.
“Binarization” is preferred over other forms of quantization because it makes a classifier algorithm more efficient. The increased efficiency is due to higher compression rates, use of CPU instead of GPU, and 200 times more speed when run on a field-programmable gate array (FPGA)
The research in the field of facial recognition is still in progress. The latest research methods have provided significant directions and pathways to implement it on a large scale.
Learn more:















