Image segmentation is the process of partitioning an image into various segments. This is an important process as it separates various objects in complex visual environments. Powerful segmentation models are also able to perform instance segmentation, where objects of the same type are detected and emphasized as belonging to the same category. Generally speaking, opaque colors are used to denote each detected segment, thus providing a visual representation of the detected segments or instances.
Segmentation models are useful to extract objects of interest for further processing and recognition. A common approach is to disregard information that does not belong to the segment or to the instance of interest, allowing subsequent models to better utilize available resources directly towards the specified task.
Our model is trained on the COCO-Stuff dataset, relying on a DeepLabv3 architecture with a ResNet-50 backbone.
Read more and try it out here.
Detic: A Detector with image classes that can use image-level labels to easily train detectors.

Detecting Twenty-thousand Classes using Image-level Supervision,
Xingyi Zhou, Rohit Girdhar, Armand Joulin, Philipp Krähenbühl, Ishan Misra,
ECCV 2022 (arXiv 2201.02605)
Detects any class given class names (using CLIP).
We train the detector on ImageNet-21K dataset with 21K classes.
Cross-dataset generalization to OpenImages and Objects365 without finetuning.
State-of-the-art results on Open-vocabulary LVIS and Open-vocabulary COCO.
Works for DETR-style detectors.
Facebook AI introduced, M2M-100 the first multilingual machine translation (MMT) model that translates between any pair of 100 languages without relying on English data.
When translating, say, Chinese to French, previous best multilingual models train on Chinese to English and English to French, because English training data is the most widely available. Their model directly trains on Chinese to French data to better preserve meaning. It outperforms English-centric systems by 10 points on the widely used BLEU metric for evaluating machine translations.
M2M-100 is trained on a total of 2,200 language directions — or 10x more than previous best, English-centric multilingual models. Deploying M2M-100 will improve the quality of translations for billions of people, especially those who speak low-resource languages.
This milestone is a culmination of years of Facebook AI’s foundational work in machine translation. They share details on how we built a more diverse MMT training dataset and model for 100 languages. They're also releasing the model, training, and evaluation setup to help other researchers reproduce and further advance multilingual models.
We've made almost 200 of these models available on Clarifai Community! Check them all out here.
YOLOv5 🚀 is a family of object detection architectures and models pretrained on the COCO dataset, and represents Ultralytics open-source research into future vision AI methods, incorporating lessons learned and best practices evolved over thousands of hours of research and development. YOLO an acronym for 'You only look once', is an object detection algorithm that divides images into a grid system. Each cell in the grid is responsible for detecting objects within itself.
YOLO is one of the most famous object detection algorithms due to its speed and accuracy.
YOLOv6 is a single-stage object detection framework dedicated to industrial applications, with hardware-friendly efficient design and high performance.

YOLOv6 has a series of models for various industrial scenarios, including N/T/S/M/L, which the architectures vary considering the model size for better accuracy-speed trade-off. And some Bag-of-freebies methods are introduced to further improve the performance, such as self-distillation and more training epochs. For industrial deployment, we adopt QAT with channel-wise distillation and graph optimization to pursue extreme performance.
YOLOv6-N hits 35.9% AP on COCO dataset with 1234 FPS on T4. YOLOv6-S strikes 43.5% AP with 495 FPS, and the quantized YOLOv6-S model achieves 43.3% AP at a accelerated speed of 869 FPS on T4. YOLOv6-T/M/L also have excellent performance, which show higher accuracy than other detectors with the similar inference speed.
YOLOv7 established a significant benchmark by taking the performance up a notch. Starting from YOLOv4, we are seeing new entries in the YOLO family one after another in a very short period of time. Each version introduces something new to improve the performance. Earlier, we have already discussed previous YOLO versions in length.
YOLO architecture is FCNN(Fully Connected Neural Network) based. However, Transformer based versions have recently been added to the YOLO family as well. We will discuss Transformer based detectors in a separate post. For now, let’s focus on FCNN (Fully Convolutional Neural Network) based YOLO object detectors.
The YOLO framework has three main components.
The Backbone mainly extracts essential features of an image and feeds them to the Head through Neck. The Neck collects feature maps extracted by the Backbone and creates feature pyramids. Finally, the head consists of output layers that have final detections. The following table shows the architectures of YOLOv4, YOLOv4, and YOLOv5.
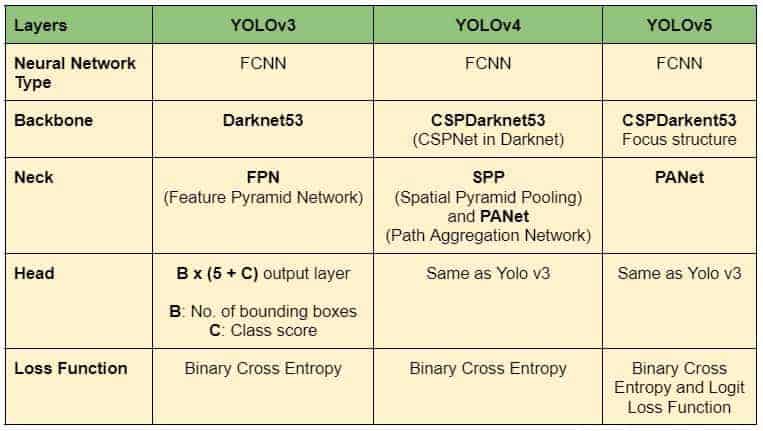
Table1: Model architecture summary of YOLOv3, YOLOv4, and YOLOv5
Apart from architectural modifications, there are several other improvements. Go through the YOLO series for detailed information.
YOLOv7 improves speed and accuracy by introducing several architectural reforms. Similar to Scaled YOLOv4, YOLOv7 backbones do not use ImageNet pre-trained backbones. Rather, the models are trained using the COCO dataset entirely. The similarity can be expected because YOLOv7 is written by the same authors of Scaled YOLOv4. The following major changes have been introduced in the YOLOv7 paper. We will go through them one by one.
This model is a fine-tuned version of xlm-roberta-base on the Language Identification dataset.
This model is an XLM-RoBERTa transformer model with a classification head on top (i.e. a linear layer on top of the pooled output). For additional information please refer to the xlm-roberta-base model card or to the paper Unsupervised Cross-lingual Representation Learning at Scale by Conneau et al.
For more info and to try it out click here.





{kind=link}