Python SDK
Released a new Python SDK as a Developer Preview
- We released the first open source version (for developer preview) of a Python SDK designed to offer you a simple, fast, and efficient way to experience the power of Clarifai’s AI platform—all with just a few lines of code.
Here's a glimpse of its key features:
- First-Class Object Interaction: The SDK provides a seamless interface for managing essential elements like apps, inputs, datasets, and models, making it easier than ever to work with these core components. You can list, create, delete (optional as applicable), or update them.
- Effortless Predictions: You can effortlessly perform predictions using both models and workflows, enabling you to leverage the power of AI for various use cases.
- Data Upload: Simplify the process of uploading image and text data, saving you time and effort in preparing your datasets for AI analysis.
You can check its documentation here and refer to examples here.
Clarifai-Python-Utils Deprecated
We have deprecated the Clarifai Python utilities project in favor of the Python SDK
- Starting from version 9.7.1, Clarifai-Python-Utils is no longer actively maintained or supported. We strongly recommend transitioning to the Python SDK, available from the 9.7.2 release onwards, as it offers improved performance and a wider range of features.
Community
Published several new, ground-breaking models
- Wrapped Claude-Instant-1.2, a fast, versatile, and cost-effective large language (LLM) model with improved math, coding, reasoning, and safety capabilities.
- Wrapped Llama2-70b-Chat, a fine-tuned Llama-2 LLM that is optimized for dialogue use cases.
- Wrapped StarCoder, an LLM with 15.5 billion parameters, excelling in code completion, modification, and explanation, specifically focused on Python, while also maintaining strong performance in other programming languages.
- Wrapped Stable Diffusion XL, a text-to-image generation model that excels in producing highly detailed and photorealistic 1024x1024 images.
- Wrapped Dolly-v2-12b, a 12 billion parameter causal LLM created by Databricks that is derived from EleutherAI's Pythia-12b and fine-tuned on a ~15K record instruction corpus generated by Databricks employees.
- Wrapped RedPajama-INCITE-7B-Chat, an LLM trained on the RedPajama base dataset, and excels in chat-related tasks. It leverages context and understanding to generate coherent and contextually relevant responses.
- Wrapped Whisper, an audio transcription model for converting speech audio to text.
- Wrapped ElevenLabs Speech Synthesis, a robust text-to-speech and voice cloning model for creating realistic speech and voices.
- Wrapped GCP Chirp ASR, a state-of-the-art, speech-to-text, speech recognition model developed by Google Cloud.
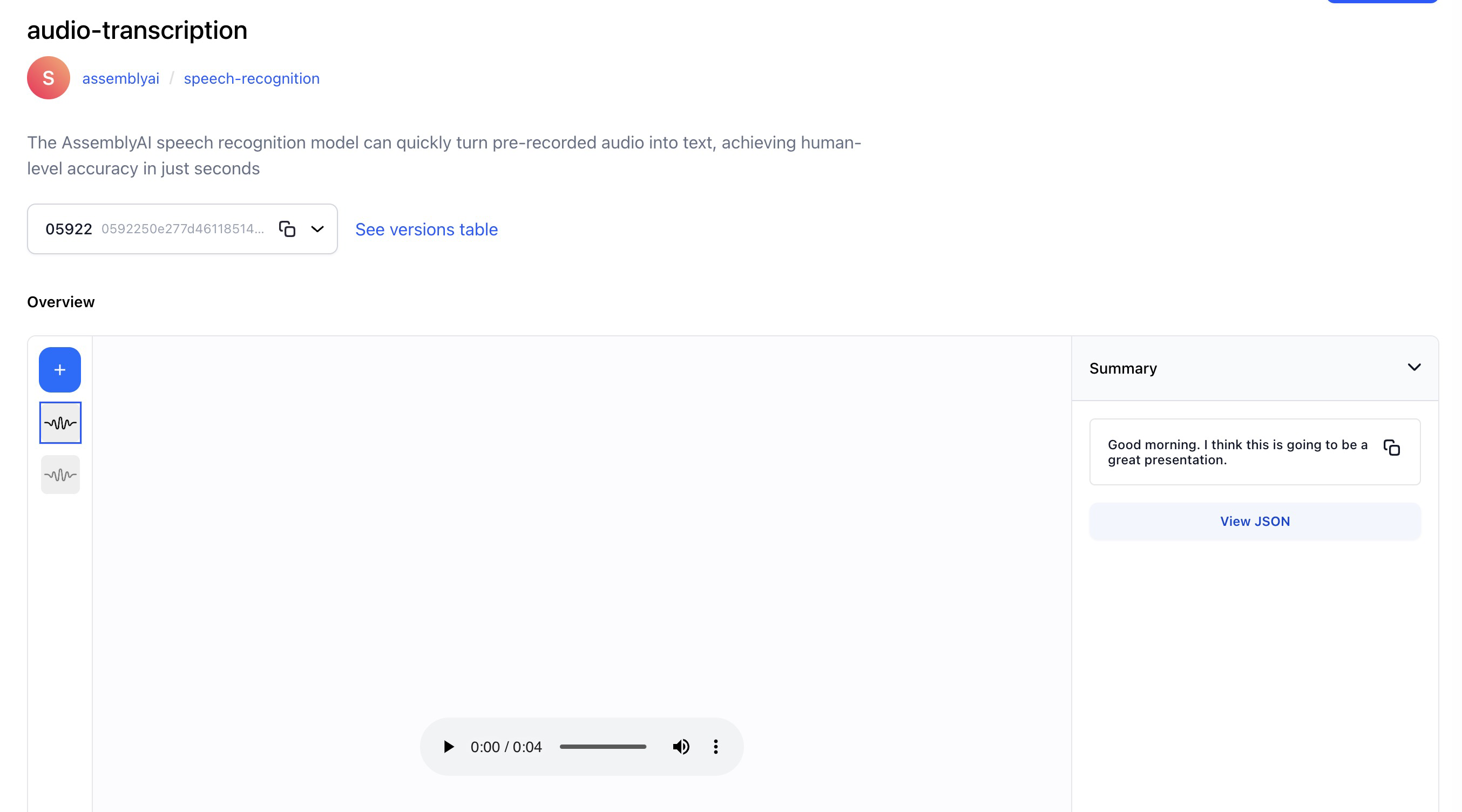
- Wrapped AssemblyAI, a speech recognition model that can quickly turn pre-recorded audio into text, achieving human-level accuracy in just seconds.
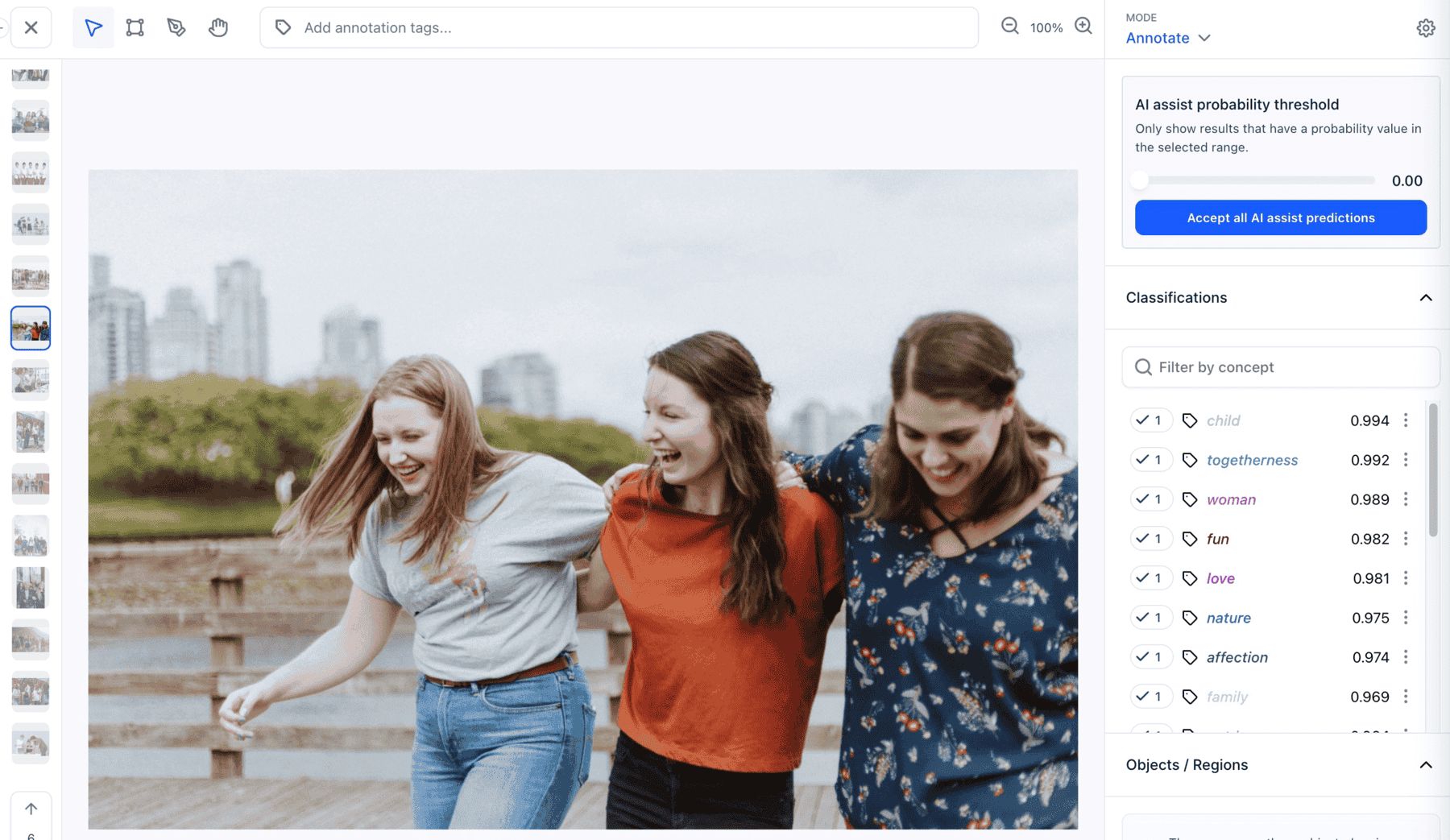
AI Assist
Added the innovative AI assist feature on the Input-Viewer screen. You can now use it to generate annotations for your inputs automatically
You can now request suggestions from any model or workflow available to you on a particular input. You can then convert the suggestions into annotations.
We fixed the following issues to ensure its proper functioning:
- Fixed an issue that previously caused the AI assist settings to reset frequently when switching between inputs. Now, the AI assist state remains persistent, ensuring a smoother experience when transitioning between inputs.
- Fixed an issue that led to app crashes when selecting a model within the AI assist modal.
- Fixed an issue that previously hindered the organization of generated labels, ensuring they are now sorted in descending order based on their concept values.
- Fixed an issue where suggestions were initially displayed with one color for concepts, but upon refreshing or accepting them, the color would change.
- Fixed an issue where the pen icon failed to appear for editing the concept list suggestions.
- Fixed the suggestion behavior so that when a user unchecks the same checkbox, it returns to being a suggestion instead of being completely removed from the list.
- We ensured that clicking on the three dots next to each label suggestion consistently opens the correct menu, without any unexpected jumps, and displays the menu's content as intended.
Smart Object Search
Introduced the smart object search (also called localized search) feature
You can now use the feature to sort, rank, and retrieve annotated objects (bounding boxes) within images based on their content and similarity.
We fixed the following issues to ensure its proper functioning:
- Fixed an issue that previously hindered the selection of a bounding box prediction nested within a larger bounding box prediction.
- Fixed an issue that prevented bounding box annotations from being created while working on a task.
Evaluation Leaderboard
Introduced a new leaderboard feature designed to streamline the process of identifying the top-performing models within a specific model type
This feature organizes models based on their evaluation results, making it effortless to access the best models for your chosen criteria.
- Organizational teams now have the capability to efficiently discover models tailored to a specific task type and evaluation dataset, allowing them to pinpoint the top-performing models effortlessly.
- Furthermore, they can delve deeper into dataset specifics, label information, and model details while conducting a comprehensive comparison of model performances.
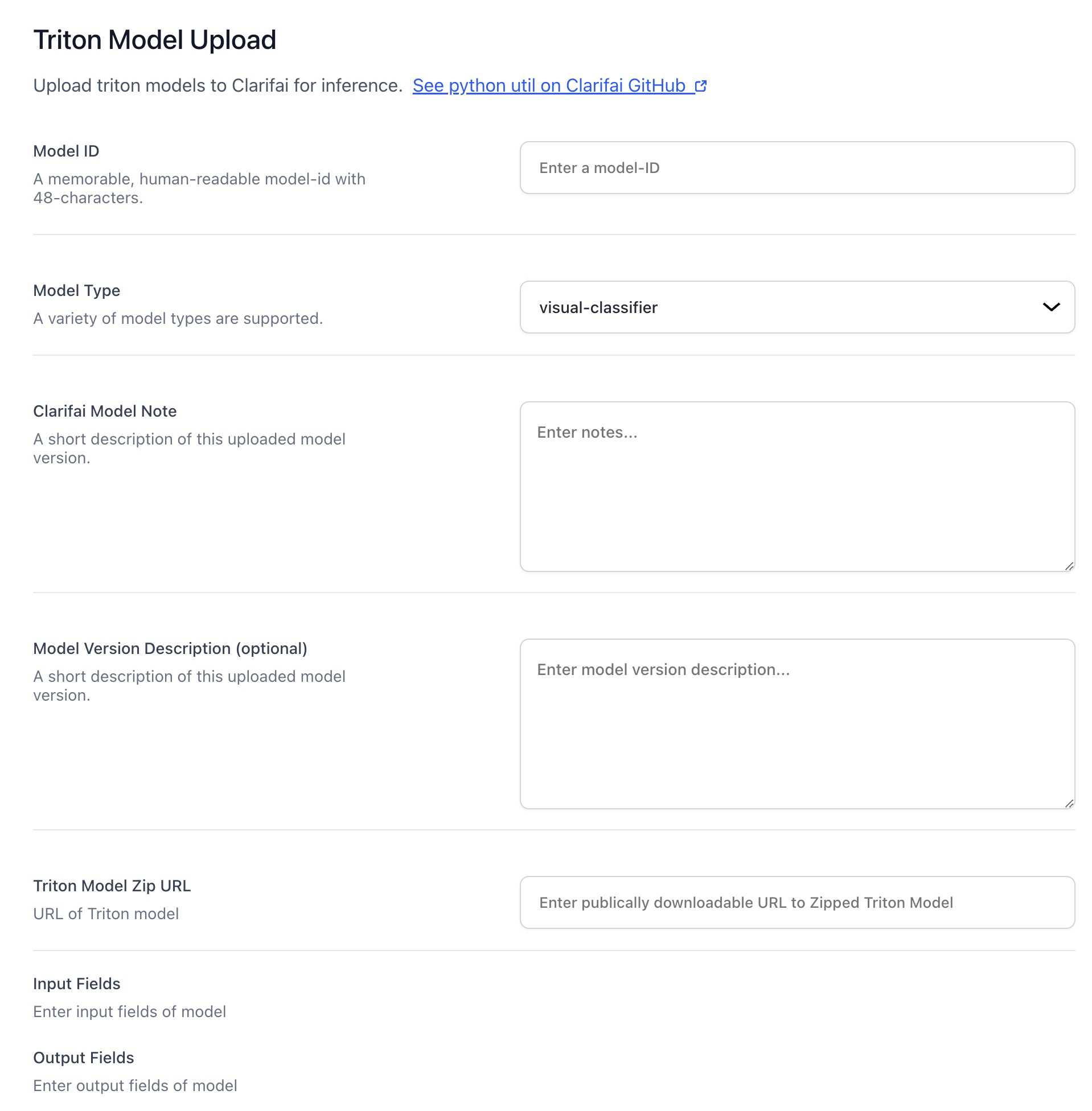
Local Model Upload UI
Introduced a valuable UI feature that allows users to upload custom-built models directly from their local development environments
- This functionality allows you to share and utilize locally trained models on our platform, converting them into Triton models effortlessly.
- Our platform supports widely used formats like TensorFlow, PyTorch, and ONNX, ensuring compatibility with your preferred development tools.
Added ability to filter inputs and annotations within the Input-Manager based on the type of data they contain
- You can now filter based on whether any text, image, video, and/or audio data is contained.
- You can now filter based on whether any bounding box, polygon, mask, point, and/or span region_info is contained.
- You can now filter based on whether any frame_info or time_info is contained.

Bug Fixes
- Fixed an issue with inconsistencies between concept IDs and concept names, which had been causing disruptions across multiple areas. When creating a new concept, its ID now mirrors its name. For instance, if you add an annotation to a dataset on the Input-Manager, the annotation ID aligns with its annotation name.
- Fixed an issue that prevented the gallery from automatically refreshing when uploading inputs on the Input-Manager. Previously, there was no automatic gallery refresh in an app's Inputs-Manager screen during input uploads, specifically when the upload progress percentage changed or when input processing was completed. We fixed the issue.
- Fixed an issue related to bulk data uploading of different data types. When you now upload a mix of data like 50 images and 5 videos simultaneously, the images are sent as a single request, whereas the videos are sent as separate requests, resulting in 5 individual requests for the 5 videos. Videos are uploaded as one per request. Other input types, including text data, are uploaded in batches of 128 each.
- Fixed an issue with the visual similarity search feature. Previously, when you clicked the magnifying glass icon located on the left side of an image, you could not initiate a visual similarity search. We fixed the issue.
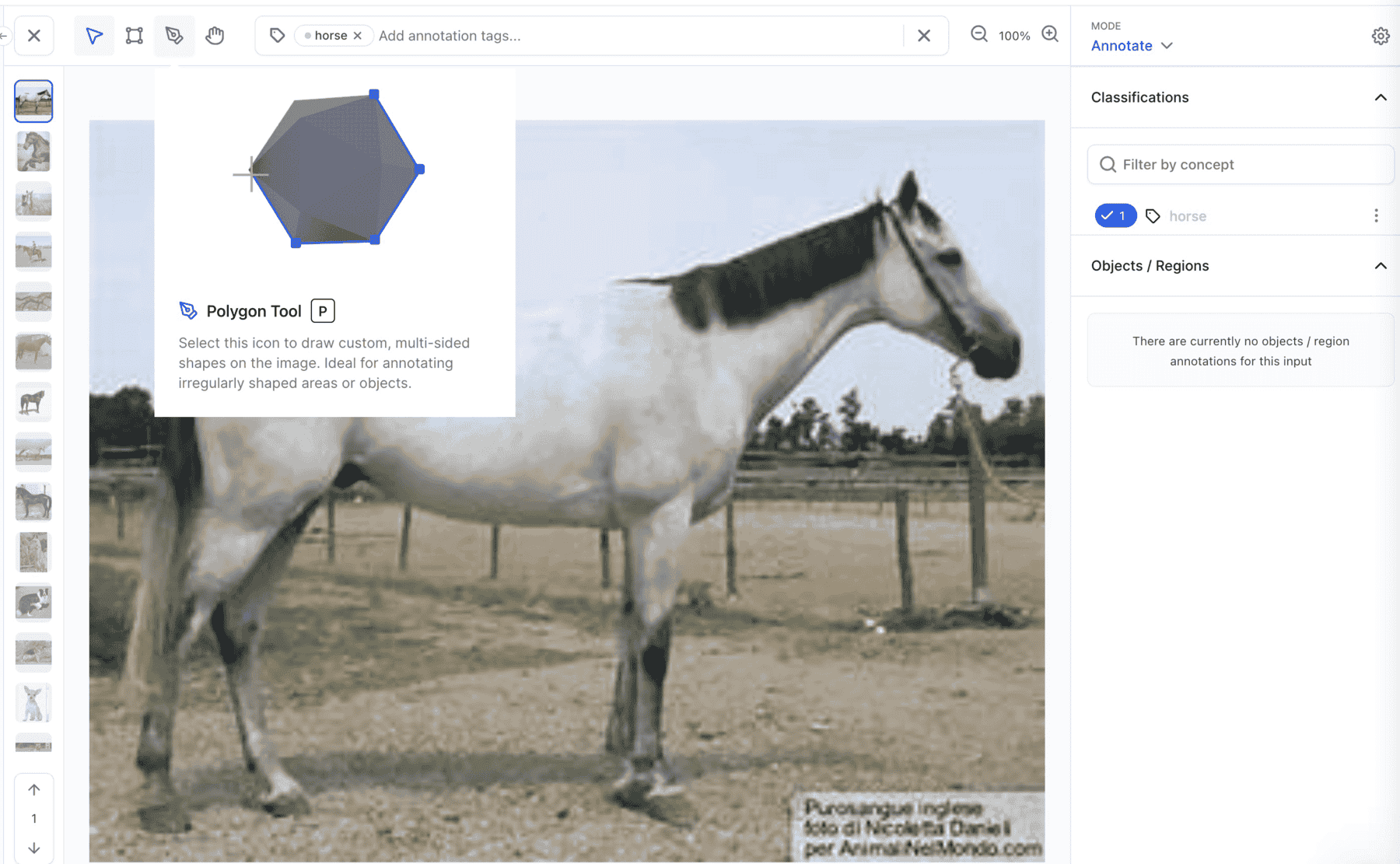
Added ability to use hotkeys to switch between annotation tools on the Input-Viewer
- We improved the accessibility and usability of the Input-Viewer by adding a new feature that enables the use of hotkeys on the annotation tools. For example, B is for the bounding box tool, P is for the polygon tool, and is H for the hand tool.
Bug Fixes
- Fixed an issue that prevented a collaborator from creating annotations on the Input-Viewer. Collaborators can now successfully create annotations on the Input-Viewer.
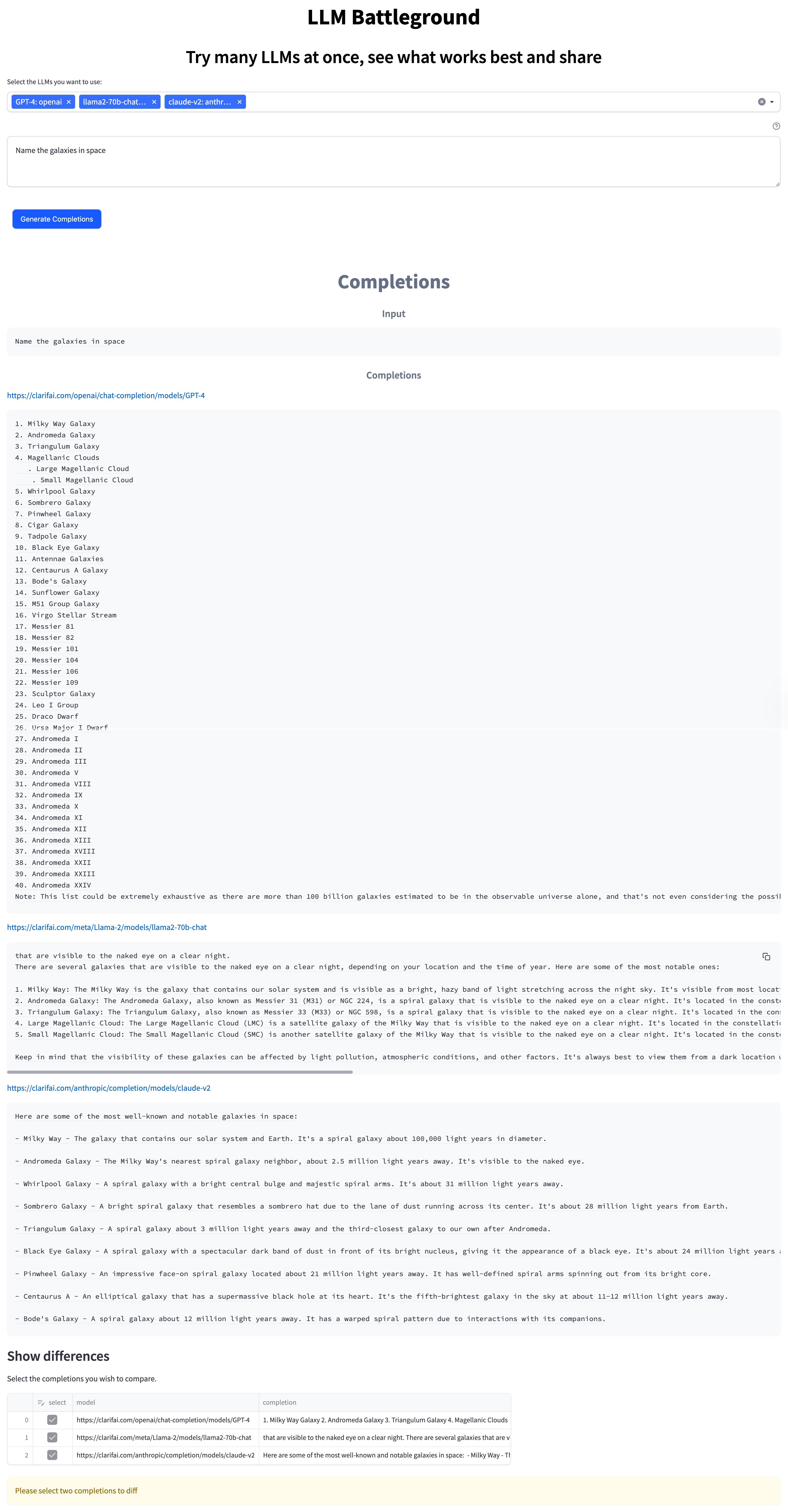
- Compare top Large Language Models side-by-side, ensuring the perfect fit for your app. You don't need to be logged in for this one!
- Check out the blog post
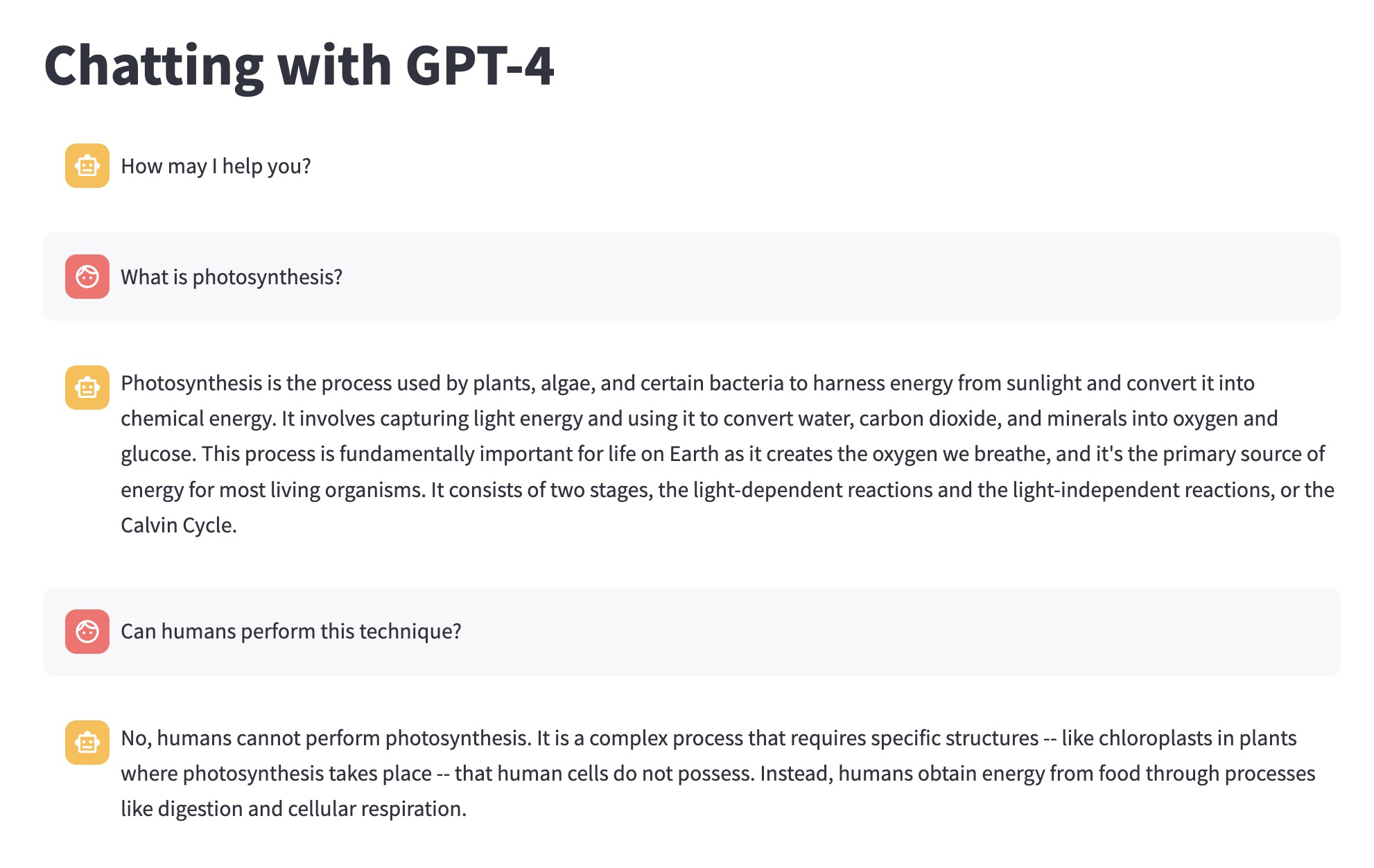
- A conversational chatbot that remembers the conversation as you go
- Upload documents such as PDFs and chat with your data! Watch this video to see it in action.
- Please note: to use this module properly, you will need to install it in your own app. Since it relies on uploaded text data, if you use it in the source application, it will refer to docs uploaded by others and give you answers related to a complete mix of random uploaded texts.

Added ability to use hotkeys to switch between annotation tools on the Input-Viewer
- Just like models, workflows, and modules, we've also added a datasets option on the collapsible left sidebar for your own and organization apps.
Improvements
- Enhanced the app overview page by introducing a dedicated section that highlights the resources available in your app—datasets, models, workflows, and modules.
- Now, at a glance, you can see the number of each resource type available in an app.
- For quick action, you can click the “add” button to add a desired resource, or click the “view” button to see a listing of the items available in your chosen resource type.
- Allowed collaborators to click the three-dot icon located on the upper-right section of the app overview page.
- Previously, this feature was exclusively accessible to the app owner, but now, collaborators with the necessary permissions can also harness its capabilities.
- Upon clicking the three-dot icon, a pop-up emerges, offering different app management options.
- Introduced valuable enhancements to the app creation process. Particularly, we added a Primary Input Type selector in the modal. This selector offers two distinct choices: you can opt for Image / Video as the primary input type or choose Text / Document based on the specific workflow requirements of your application. This enables you to choose the most suitable default base workflow for the type of input you intend to utilize in your application. Nonetheless, you can still choose any other workflow manually.
- Made minor improvements.
- Removed the “NEW” tag from the “Labeling Tasks” (previously called "Labeller") option on the collapsible left sidebar. It's also now being listed under the AI Lake.
- Fixed broken "Learn more..." links scattered across various pages that list resources within an app.
Bug Fixes
- Fixed an issue where creating apps on the Safari web browser failed. Creating apps on the Safari web browser now works as desired.
- Fixed an issue where the length of a long app name exceeded the provided field. App names of varying lengths can now be accommodated within the specified field without causing any display issues.
- Fixed an issue with the search functionality for organizational apps. Previously, if you searched for specific apps within your organization, no search results were returned. We fixed the issue.
Improvements
- Transitioned dataset information handling for model version creation.
- Previously, dataset info was only stored in
train_info.params.dataset_id and train_info.params.dataset_version_id . We included an additional check for train_info.dataset and train_info.dataset.version in the model type fields, which take precedence if available.
- We also added two new field types,
(DATASET and DATASET_VERSION), to replace the older ID-based fields, enabling the use of actual dataset objects and facilitating compatibility with datasets from other applications in the future.
- Improved the "Use Model / Use Workflow" modal pop-up.
- When you click either the "Use Model" or the "Use Workflow" button on the respective model's or workflow's page, a pop-up window will appear.
- We streamlined the user experience by placing the "Call by API" tab as the initial option within this window. Previously, the "Use in a Workflow / App" tab held this position, but we prioritized the more common "Call by API" functionality for easier access.
- We also enhanced accessibility by positioning Python as the primary option among the programming languages with code snippets.
- We also updated the code snippets for text models, setting raw text as the default option for making predictions. Predicting via local files and via URLs are still available as optional alternatives.
- Created new model versions for person detector models without cropping, as cropping is causing these models to miss people on the margins. We duplicated the existing model versions and modified the data provider parameters to include downsampling, resizing, and padding only, in alignment with the standard upload process for new visual models.
- Improved the presentation of the JSON output generated from model predictions.
- Previously, the JSON output would extend beyond the borders of the display modal screen, causing inconvenience.
- We also improved the user experience by making the button for copying all the output contents more user-friendly and intuitive.
- Improved the prediction area for Community models to show a "sign up or log in" prompt for users who are not currently logged in. Previously, when you were not logged in, the Community model output section showed an "insufficient scopes" error. We now intercept the error and instead prompt users to log in or sign up—while showing the default predictions.
Bug Fixes
- Fixed an issue that caused an application to crash. Previously, if you clicked the "Use Model" button and then selected the "Call by API" option for certain models, the application crashed. We fixed the issue.
- Fixed an issue where an unexpected pop-up window appeared while carrying out various actions. The rogue pop-up interruption is no longer visible when adding models to workflows, when clicking the "Cancel" button while choosing the model path, or when creating a new app.
- Fixed an issue where it was not possible to view the evaluation metrics of old transfer learned models. Previously, you could not access the evaluation metrics for older transfer learning models, as the drop-down menu lacked the option to select a dataset. That limitation applied to all transfer learning models that were trained and evaluated prior to the implementation of the changes on how the evaluation metrics work.
- Fixed an issue where the base_model for transfer learning models did not display a list of the available base models. All the models from the base workflow that produce embeddings are currently listed.
Improvements
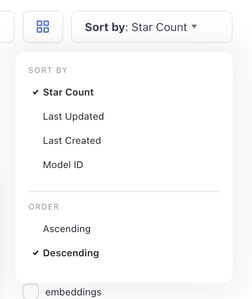
- Changed the default sorting criteria for resources.
- We changed the default sorting criteria for the resources you own—apps, models, workflows, modules, and datasets—to Last Updated.
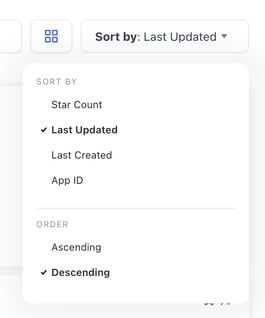
- The default sorting criteria for Community resources is still by Star Count.
Improvements
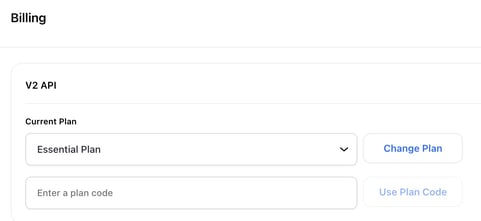
- Enabled a user's active subscription plan to be visible on the billing page. You can now view the correct subscription plan you're enrolled in directly on the billing page. It's also included in the drop-down options in case you wish to explore or switch to another plan.
Introduced a quick way to filter both large language models (LLMs) and image generation (text-to-image) models, making it easier to find the models you need
- You can now streamline your search by simply clicking a checkbox in the right sidebar to show exclusively the available LLMs on the Community platform. This same convenient feature applies to image generation models as well.